Pandas-DataFrame知识点汇总
1、DataFrame的创建
DataFrame是一种表格型数据结构,它含有一组有序的列,每列可以是不同的值。DataFrame既有行索引,也有列索引,它可以看作是由Series组成的字典,不过这些Series公用一个索引。
DataFrame的创建有多种方式,不过最重要的还是根据dict进行创建,以及读取csv或者txt文件来创建。这里主要介绍这两种方式。
根据字典创建
data = {
'state':['Ohio','Ohio','Ohio','Nevada','Nevada'],
'year':[2000,2001,2002,2001,2002],
'pop':[1.5,1.7,3.6,2.4,2.9]
}
frame = pd.DataFrame(data)
frame
#输出
pop state year
0 1.5 Ohio 2000
1 1.7 Ohio 2001
2 3.6 Ohio 2002
3 2.4 Nevada 2001
4 2.9 Nevada 2002
DataFrame的行索引是index,列索引是columns,我们可以在创建DataFrame时指定索引的值:
frame2 = pd.DataFrame(data,index=['one','two','three','four','five'],columns=['year','state','pop','debt']) frame2 #输出 year state pop debt one 2000 Ohio 1.5 NaN two 2001 Ohio 1.7 NaN three 2002 Ohio 3.6 NaN four 2001 Nevada 2.4 NaN five 2002 Nevada 2.9 NaN
使用嵌套字典也可以创建DataFrame,此时外层字典的键作为列,内层键则作为索引:
pop = {'Nevada':{2001:2.4,2002:2.9},'Ohio':{2000:1.5,2001:1.7,2002:3.6}}
frame3 = pd.DataFrame(pop)
frame3
#输出
Nevada Ohio
2000 NaN 1.5
2001 2.4 1.7
2002 2.9 3.6
我们可以用index,columns,values来访问DataFrame的行索引,列索引以及数据值,数据值返回的是一个二维的ndarray
frame2.values #输出 array([[2000, 'Ohio', 1.5, 0], [2001, 'Ohio', 1.7, 1], [2002, 'Ohio', 3.6, 2], [2001, 'Nevada', 2.4, 3], [2002, 'Nevada', 2.9, 4]], dtype=object)
读取文件
读取文件生成DataFrame最常用的是read_csv,read_table方法。
该方法中几个重要的参数如下所示:
| 参数 | 描述 |
|---|---|
| header | 默认第一行为columns,如果指定header=None,则表明没有索引行,第一行就是数据 |
| index_col | 默认作为索引的为第一列,可以设为index_col为-1,表明没有索引列 |
| nrows | 表明读取的行数 |
| sep或delimiter | 分隔符,read_csv默认是逗号,而read_table默认是制表符\t |
| encoding | 编码格式 |
其他创建DataFrame的方式有很多,比如我们可以通过读取mysql或者mongoDB来生成,也可以读取json文件等等,这里就不再介绍。
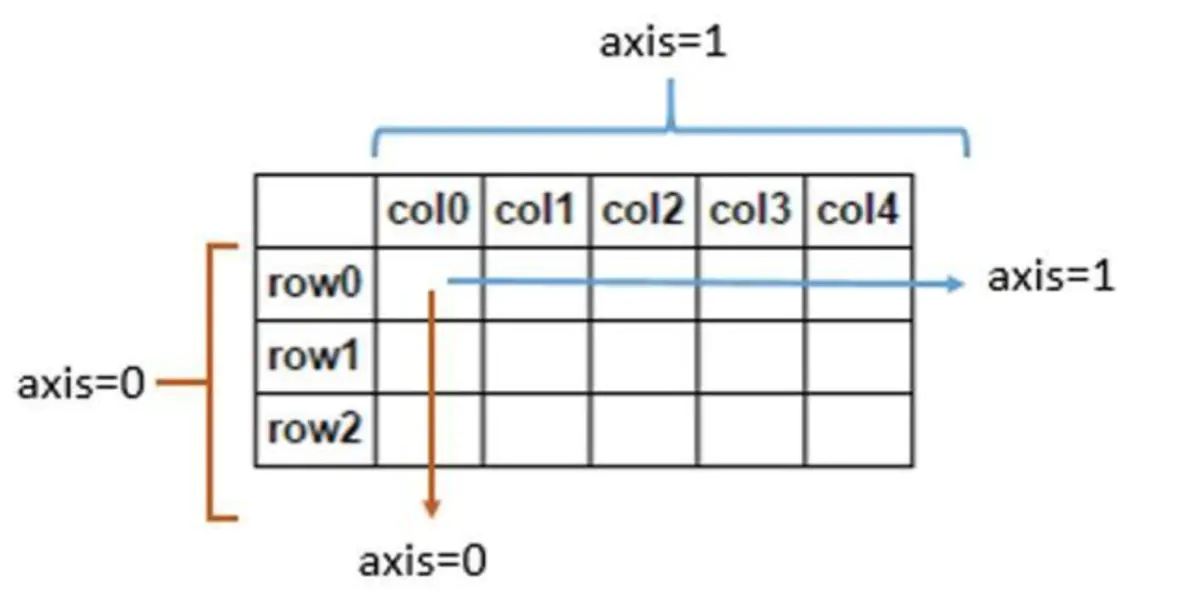
2、DataFrame轴的概念
在DataFrame的处理中经常会遇到轴的概念,这里先给大家一个直观的印象,我们所说的axis=0即表示沿着每一列或行标签\索引值向下执行方法,axis=1即表示沿着每一行或者列标签模向执行对应的方法。
3、DataFrame一些性质
索引、切片
我们可以根据列名来选取一列,返回一个Series:
frame2['year'] #输出 one 2000 two 2001 three 2002 four 2001 five 2002 Name: year, dtype: int64
我们还可以选取多列或者多行:
data = pd.DataFrame(np.arange(16).reshape((4,4)),index = ['Ohio','Colorado','Utah','New York'],columns=['one','two','three','four']) data[['two','three']] #输出 two three Ohio 1 2 Colorado 5 6 Utah 9 10 New York 13 14 #取行 data[:2] #输出 one two three four Ohio 0 1 2 3 Colorado 4 5 6 7
当然,在选取数据的时候,我们还可以根据逻辑条件来选取:
data[data['three']>5] #输出 one two three four Colorado 4 5 6 7 Utah 8 9 10 11 New York 12 13 14 15
pandas提供了专门的用于索引DataFrame的方法,即使用ix方法进行索引,不过ix在最新的版本中已经被废弃了,如果要是用标签,最好使用loc方法,如果使用下标,最好使用iloc方法:
#data.ix['Colorado',['two','three']] data.loc['Colorado',['two','three']] #输出 two 5 three 6 Name: Colorado, dtype: int64 data.iloc[0:3,2] #输出 Ohio 2 Colorado 6 Utah 10 Name: three, dtype: int64
修改数据
可以使用一个标量修改DataFrame中的某一列,此时这个标量会广播到DataFrame的每一行上:
data = {
'state':['Ohio','Ohio','Ohio','Nevada','Nevada'],
'year':[2000,2001,2002,2001,2002],
'pop':[1.5,1.7,3.6,2.4,2.9]
}
frame2 = pd.DataFrame(data,index=['one','two','three','four','five'],columns=['year','state','pop','debt'])
frame2
frame2['debt']=16.5
frame2
#输出
year state pop debt
one 2000 Ohio 1.5 16.5
two 2001 Ohio 1.7 16.5
three 2002 Ohio 3.6 16.5
four 2001 Nevada 2.4 16.5
five 2002 Nevada 2.9 16.5
也可以使用一个列表来修改,不过要保证列表的长度与DataFrame长度相同:
frame2.debt = np.arange(5) frame2 #输出 year state pop debt one 2000 Ohio 1.5 0 two 2001 Ohio 1.7 1 three 2002 Ohio 3.6 2 four 2001 Nevada 2.4 3 five 2002 Nevada 2.9 4
可以使用一个Series,此时会根据索引进行精确匹配:
val = pd.Series([-1.2,-1.5,-1.7],index=['two','four','five']) frame2['debt'] = val frame2 #输出 year state pop debt one 2000 Ohio 1.5 NaN two 2001 Ohio 1.7 -1.2 three 2002 Ohio 3.6 NaN four 2001 Nevada 2.4 -1.5 five 2002 Nevada 2.9 -1.7
重新索引
使用reindex方法对DataFrame进行重新索引。对DataFrame进行重新索引,可以重新索引行,列或者两个都修改,如果只传入一个参数,则会从新索引行:
frame = pd.DataFrame(np.arange(9).reshape((3,3)),index=[1,4,5],columns=['Ohio','Texas','California']) frame2 = frame.reindex([1,2,4,5]) frame2 #输出 Ohio Texas California 1 0.0 1.0 2.0 2 NaN NaN NaN 4 3.0 4.0 5.0 5 6.0 7.0 8.0 states = ['Texas','Utah','California'] frame.reindex(columns=states) #输出 Texas Utah California 1 1 NaN 2 4 4 NaN 5 5 7 NaN 8
填充数据只能按行填充,此时只能对行进行重新索引:
frame = pd.DataFrame(np.arange(9).reshape((3,3)),index = ['a','c','d'],columns = ['Ohio','Texas','California']) frame.reindex(['a','b','c','d'],method = 'bfill') #frame.reindex(['a','b','c','d'],method = 'bfill',columns=states) 报错
丢弃指定轴上的值
可以使用drop方法丢弃指定轴上的值,不会对原DataFrame产生影响
frame = pd.DataFrame(np.arange(9).reshape((3,3)),index = ['a','c','d'],columns = ['Ohio','Texas','California'])
frame.drop('a')
#输出
Ohio Texas California
a 0 1 2
c 3 4 5
d 6 7 8
frame.drop(['Ohio'],axis=1)
#输出
Texas California
a 1 2
c 4 5
d 7 8
算术运算
DataFrame在进行算术运算时会进行补齐,在不重叠的部分补足NA:
df1 = pd.DataFrame(np.arange(9).reshape((3,3)),columns=list('bcd'),index=['Ohio','Texas','Colorado'])
df2 = pd.DataFrame(np.arange(12).reshape((4,3)),columns = list('bde'),index=['Utah','Ohio','Texas','Oregon'])
df1 + df2
#输出
b c d e
Colorado NaN NaN NaN NaN
Ohio 3.0 NaN 6.0 NaN
Oregon NaN NaN NaN NaN
Texas 9.0 NaN 12.0 NaN
Utah NaN NaN NaN NaN
可以使用fill_value方法填充NA数据,不过两个df中都为NA的数据,该方法不会填充:
df1.add(df2,fill_value=0) #输出 b c d e Colorado 6.0 7.0 8.0 NaN Ohio 3.0 1.0 6.0 5.0 Oregon 9.0 NaN 10.0 11.0 Texas 9.0 4.0 12.0 8.0 Utah 0.0 NaN 1.0 2.0
函数应用和映射
numpy的元素级数组方法,也可以用于操作Pandas对象:
frame = pd.DataFrame(np.random.randn(3,3),columns=list('bcd'),index=['Ohio','Texas','Colorado'])
np.abs(frame)
#输出
b c d
Ohio 0.367521 0.232387 0.649330
Texas 3.115632 1.415106 2.093794
Colorado 0.714983 1.420871 0.557722
另一个常见的操作是,将函数应用到由各列或行所形成的一维数组上。DataFrame的apply方法即可实现此功能。
f = lambda x:x.max() - x.min() frame.apply(f) #输出 b 3.830616 c 2.835978 d 2.743124 dtype: float64 frame.apply(f,axis=1) #输出 Ohio 1.016851 Texas 4.530739 Colorado 2.135855 dtype: float64 def f(x): return pd.Series([x.min(),x.max()],index=['min','max']) frame.apply(f) #输出 b c d min -0.714983 -1.415106 -0.649330 max 3.115632 1.420871 2.093794
元素级的Python函数也是可以用的,使用applymap方法:
format = lambda x:'%.2f'%x frame.applymap(format) #输出 b c d Ohio 0.37 -0.23 -0.65 Texas 3.12 -1.42 2.09 Colorado -0.71 1.42 -0.56
排序和排名
对于DataFrame,sort_index可以根据任意轴的索引进行排序,并指定升序降序
frame = pd.DataFrame(np.arange(8).reshape((2,4)),index=['three','one'],columns=['d','a','b','c']) frame.sort_index() #输出 d a b c one 4 5 6 7 three 0 1 2 3 frame.sort_index(1,ascending=False) #输出 d a b c one 4 5 6 7 three 0 1 2 3
DataFrame也可以按照值进行排序:
#按照任意一列或多列进行排序 frame.sort_values(by=['a','b']) #输出 d a b c three 0 1 2 3 one 4 5 6 7
汇总和计算描述统计
DataFrame中的实现了sum、mean、max等方法,我们可以指定进行汇总统计的轴,同时,也可以使用describe函数查看基本所有的统计项:
df = pd.DataFrame([[1.4,np.nan],[7.1,-4.5],[np.nan,np.nan],[0.75,-1.3]],index=['a','b','c','d'],columns=['one','two']) df.sum(axis=1) #输出 one 9.25 two -5.80 dtype: float64 #Na会被自动排除,可以使用skipna选项来禁用该功能 df.mean(axis=1,skipna=False) #输出 a NaN b 1.300 c NaN d -0.275 dtype: float64 #idxmax返回间接统计,是达到最大值的索引 df.idxmax() #输出 one b two d dtype: object #describe返回的是DataFrame的汇总统计 #非数值型的与数值型的统计返回结果不同 df.describe() #输出 one two count 3.000000 2.000000 mean 3.083333 -2.900000 std 3.493685 2.262742 min 0.750000 -4.500000 25% 1.075000 -3.700000 50% 1.400000 -2.900000 75% 4.250000 -2.100000 max 7.100000 -1.300000
DataFrame也实现了corr和cov方法来计算一个DataFrame的相关系数矩阵和协方差矩阵,同时DataFrame也可以与Series求解相关系数。
frame1 = pd.DataFrame(np.random.randn(3,3),index=list('abc'),columns=list('abc'))
frame1.corr
#输出
<bound method DataFrame.corr of a b c
a 1.253773 0.429059 1.535575
b -0.113987 -2.837396 -0.894469
c -0.548208 0.834003 0.994863>
frame1.cov()
#输出
a b c
a 0.884409 0.357304 0.579613
b 0.357304 4.052147 2.442527
c 0.579613 2.442527 1.627843
#corrwith用于计算每一列与Series的相关系数
frame1.corrwith(frame1['a'])
#输出
a 1.000000
b 0.188742
c 0.483065
dtype: float64
处理缺失数据
Pandas中缺失值相关的方法主要有以下三个:
- isnull方法用于判断数据是否为空数据;
- fillna方法用于填补缺失数据;
- dropna方法用于舍弃缺失数据。
上面两个方法返回一个新的Series或者DataFrame,对原数据没有影响,如果想在原数据上进行直接修改,使用inplace参数:
data = pd.DataFrame([[1,6.5,3],[1,np.nan,np.nan],[np.nan,np.nan,np.nan],[np.nan,6.5,3]]) data.dropna() #输出 0 1 2 0 1.0 6.5 3.0
对DataFrame来说,dropna方法如果发现缺失值,就会进行整行删除,不过可以指定删除的方式,how=all,是当整行全是na的时候才进行删除,同时还可以指定删除的轴。
data.dropna(how='all',axis=1,inplace=True)
data
#输出
0 1 2
0 1.0 6.5 3.0
1 1.0 NaN NaN
2 NaN NaN NaN
3 NaN 6.5 3.0
DataFrame填充缺失值可以统一填充,也可以按列填充,或者指定一种填充方式:
data.fillna({1:2,2:3})
#输出
0 1 2
0 1.0 6.5 3.0
1 1.0 2.0 3.0
2 NaN 2.0 3.0
3 NaN 6.5 3.0
data.fillna(method='ffill')
#输出
0 1 2
0 1.0 6.5 3.0
1 1.0 6.5 3.0
2 1.0 6.5 3.0
3 1.0 6.5 3.0
到此这篇关于Pandas-DataFrame知识点汇总的文章就介绍到这了,更多相关Pandas-DataFrame内容请搜索源码搜藏网以前的文章或继续浏览下面的相关文章希望大家以后多多支持源码搜藏网!
ajax教程阅读排行
-

ajax post 提交大数据量 - Web 开发 / Ajax
2013-04-25
-
使用Ajax 实现页面局部刷新 支持H5的浏览器会保留访问痕迹 链接
2014-05-05
-
2013-04-25
-
2013-04-25
-

如何使用jQuery Post方法调用OpenWeatherMap API?
2019-03-04
-
2013-04-24
-

2013-04-24
-
2012-08-28
最新文章
-
2022-03-17
-
2022-03-17
-
2022-03-17
-
2022-03-17
-

2022-03-16
-
2022-03-16
-
2022-03-16
-

2022-03-16
热门源码
