C++高性能静态缓冲字符串
这个类是为了替代创建POD C字符串(CS)的概念,这显然是对穷人的设计主题(我个人认为这是对worsests解决方案之一的沿空指针)。相比于 CS的 StaticallyBufferedString显著提升双方的速度,安全性和功能性。
背景
随着引进了C++的总会有一个替代原有的C风格的东西:指针- >引用,POD C字符串 - > 的std ::字符串,的malloc / 免费 - > 新 / 删除,结构- >类,宏观 - > 模板和#define MAX 127 - >静态const int的MAX = 127等。
该标准::字符串类是一个很好的,可接受的解决方案,除了一件事:集中存储模式。这是默认的动态。虽然它具有的possibilty利于实时大小控制,在成本使用的堆内存有时太高。这两种锁(如果我们不使用 专用堆 不知)和碎片导致它。通过优化内存分配 prereserving内存 是提高了一个整体性能的好办法,但它仍然涉及到所有基于堆的分配问题。当然,你可以提供自己的分配器由使用 的std :: string的类,但写你自己的分配器是不是真的一个简单的问题,那是不是我想说的是原本为止。
使用的另一个原因 的容器与固定容量存储器池是(espically与串),在对象的平均和最大尺寸generatlly众所周知的(由于预定义的限制),或至少不硬的大多数情况下进行预测(usally由统计数据收集)。
还有一个 对内存分配失败数学保证使用内存池时(假设你正确地计算所需的最低池大小)。
类说明
该类方法通常设计提供 的std :: string的 一样的界面,但也有值得注意的事情提一些具体的方法来描述。
类模板被设计成与不同类型的符号的工作
// 'TElemType' - char / wchar_t / char16_t / char32_t (provides POD C str. if 'TElemType' is a char)
template<typename TElemType, const size_t MaxLen>
(通过我的基本字符准确地测试了它只能作为其他char型我个人并不reallly需要和其他开发人员很少使用它太)。
主类特征是:
// 不是线程安全的,无泄漏,无抛出保证
这个类提供自动生成的哈希函数对象
ADD_HASHER_FOR(TThisType, hasher)
从 HashUtils模块
#define ADD_HASHER_FOR(ClassName, HasherName) \
template <typename T = ClassName>\
struct HasherName {\
auto operator()(const T& obj) const throw() -> decltype(obj.hash()) {\
return obj.hash();\
}\
};
支持 哈希容器。
为用户提供一些兼容性STL旗,类定义了 模拟对象类型作为internall 分配器类型(如无分配器真的在这里参与)
typedef AllocatorInterface<TElemType> allocator_type; // mock object type
AllocatorInterface 模块是非常简单,自我描述
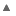 复制代码
复制代码
ifndef AllocatorInterfaceH
#define AllocatorInterfaceH
#include <memory>
// C++ allocator concept: http://en.cppreference.com/w/cpp/concept/Allocator
// Fake allocator, which can NOT AND would NOT work!
// Derived classes SHOULD specify the following properties:
// 'propagate_on_container_copy_assignment', 'propagate_on_container_move_assignment',
// 'propagate_on_container_swap' AND 'is_always_equal' (if req.)
template <class T>
class AllocatorInterface : public std::allocator<T> { // better derive from the 'allocator_traits'
public:
//// MS VS does NOT need this aliases, but GCC does
typedef typename std::allocator<T> TBaseAllocatorType;
typedef typename TBaseAllocatorType::pointer pointer;
typedef typename TBaseAllocatorType::const_pointer const_pointer;
typedef typename TBaseAllocatorType::reference reference;
typedef typename TBaseAllocatorType::const_reference const_reference;
typedef typename TBaseAllocatorType::size_type size_type;
//// Three constructor versions must be defined (even if they do nothing)
//// to allow for copy-constructions from allocator objects of other types
AllocatorInterface() = default;
AllocatorInterface(const AllocatorInterface&) = default;
template <class U>
AllocatorInterface(AllocatorInterface<U>&&) throw() {}
// [!] NO member of the standard default allocator class template shall introduce data races,
// calls to member functions that allocate or deallocate storage shall occur in a single total order
// and each such deallocation shall happen before the next allocation (if any) in this order [!]
virtual ~AllocatorInterface() = default;
virtual pointer address(reference ref) const throw() {
return std::allocator<T>::address(ref);
}
virtual const_pointer address(const_reference ref) const throw() {
return std::allocator<T>::address(ref);
}
//// Pure virtual
virtual pointer allocate(size_type count, std::allocator<void>::const_pointer hint = nullptr) = 0;
virtual void deallocate(pointer addr, size_type count) = 0;
virtual size_type max_size() const throw() {
return size_type();
}
//// 'construct ' AND 'destroy' are both template funcs.
//// so can NOT be virtual (they will be used from a 'std::allocator')
//// Custom allocators may contain state:
//// each container or another allocator-aware object stores an instance of the supplied allocator
//// and controls allocator replacement through 'std::allocator_traits'
private:
};
template <typename T, class U>
bool operator==(const AllocatorInterface<T>&, const AllocatorInterface<U>&) throw() {
return false;
}
template <typename T, class U>
bool operator!=(const AllocatorInterface<T>& alloc1, const AllocatorInterface<U>& alloc2) throw() {
return !(alloc1 == alloc2);
}
#endif // AllocatorInterfaceH
字符串是可迭代的,因为它采用的是 通用随机访问迭代器
typedef GenericRAIterator<StaticallyBufferedStringLight,
value_type, false, false> iterator;
typedef GenericRAIterator<StaticallyBufferedStringLight,
value_type, true, false> reverse_iterator;
typedef GenericRAIterator<StaticallyBufferedStringLight,
value_type, false, true> const_iterator;
typedef GenericRAIterator<StaticallyBufferedStringLight,
value_type, true, true> const_reverse_iterator;
但在没有恒定irterators应使用非常仔细地使用它们来修改内部的字符序列是一个明确的和简单的方法来打破对象 的状态(例如,一个简单的方法这样做是把一个字符串结束- '\ 0'改变这样一个实际的字符串长度序列)和中间关联性(缓存哈希),那些需要该类强行恢复它的是状态开不直接支持 目前。
我公司提供无const的irterators,以提高整体flexebility和类的versatality,通过我想他们should't使用,除非用户显然undestands他在做什么。
(有是通过提供一个固定的行为方式代理对象 ,而不是由真正的字符参考下标运算符,但我不知道 是不是真的需要)。
类的大多数功能是模板化以提供与其他可能的storrage类型兼容性(如果它们satisfys的要求)。
// Compatible with the ANY storage class which has 'TElemType' as an elem. type
// AND provides the null-terminated str. by the public const member 'c_str'
// (like std::string, StaticallyBufferedStringLight<ANY SIZE> etc)
template<typename TStorageType>
StaticallyBufferedStringLight& operator=(const TStorageType& str) throw() {
定制 的strcmp 从功能 MemUtils 用于comapre多的字符串模块(和不同的)的类型
template<const size_t CmpChunkSize = sizeof(std::uintptr_t), // in bytes
const bool SignedCmpChunk = false, // as 'strcmp' by default [7.21.4/1 (C99)]
typename TElem1Type, typename TElem2Type>
typename IntegralTypeBySize<CmpChunkSize, true>::Type
// Used to compare strings with the diff. char types
// Works almost as fast as a 'strcmp' (at least for 'char' AND on release)
// [!] Does NOT checks an incoming args. on validity [!]
strCmp(const TElem1Type* mem1, const TElem2Type* mem2) throw()
{
typedef typename IntegralTypeBySize<sizeof(*mem1), false>::Type TUE1T; // unsigned both
typedef typename IntegralTypeBySize<sizeof(*mem2), false>::Type TUE2T;
typedef typename IntegralTypeBySize<CmpChunkSize, true>::Type TReturnType;
// See http://stackoverflow.com/questions/1356741/strcmp-and-signed-unsigned-chars
static_assert(sizeof(TReturnType) > sizeof(*mem1) &&
sizeof(TReturnType) > sizeof(*mem2), "Incorrect elem. type size");
if (mem1 == mem2) return TReturnType(); // optimization
typename IntegralTypeBySize<CmpChunkSize, SignedCmpChunk>::Type elem1, elem2;
while (true) {
elem1 = static_cast<decltype(elem1)>(static_cast<TUE1T>(*mem1));
elem2 = static_cast<decltype(elem2)>(static_cast<TUE2T>(*mem2));
if (!elem1 || elem1 != elem2)
return static_cast<TReturnType>(elem1) - elem2;
++mem1, ++mem2;
}
}
也有流状运营商定义的Concat的。的数字的字符串:
// Same as the 'append(const TValueType value)'
template<typename TValueType,
class = typename // remove from the overload resolution to avoid an ambiguity
std::enable_if<std::is_arithmetic<TValueType>::value &&
!std::is_pointer<TValueType>::value && // 'std::nullptr_t' is OK
!std::is_same<TValueType, TElemType>::value>::type>
StaticallyBufferedStringLight& operator<<(const TValueType value) throw() {
append(value);
return *this;
}
StaticallyBufferedStringLight& operator<<(const TElemType* const str) throw() {
append(str);
return *this;
}
正如你所看到的SFINAE通过的std :: enable_if和其他类型的特征公用事业这里所涉及的,以确保这些运营商仅用于与正确的类型。
非标准名称空间是ELSO增强,增加了STL的兼容性
复制代码
namespace std {
template<typename TElemType, const size_t MaxLen>
bool operator==(const std::string& dStr,
const StaticallyBufferedStringLight<TElemType, MaxLen>& sStr) throw() {
return sStr == dStr;
}
template<typename TElemType, const size_t MaxLen>
bool operator==(const TElemType* const cStr,
const StaticallyBufferedStringLight<TElemType, MaxLen>& sStr) throw() {
return sStr == cStr;
}
template<typename TElemType, const size_t MaxLen>
std::ostream& operator<<(std::ostream& stream,
const StaticallyBufferedStringLight<TElemType, MaxLen>& str) {
stream << str.c_str(); // OPTIMIZATION: reserve internal buffer first
return stream;
}
template<typename TElemType, const size_t MaxLen>
std::istream& operator>>(std::istream& stream,
StaticallyBufferedStringLight<TElemType, MaxLen>& str) {
auto symb = stream.get(); // skip first (it is '\n')
while (true) {
symb = stream.get(); // on EOF - 'failbit' flag is set
switch (symb) {
case '\n': case '\r': return stream; // escape char.
}
if (!stream) break; // true if either 'failbit' or 'badbit' flag is set
if (!str.push_back(symb)) break;
}
return stream;
}
};
随着海峡。有非常严格的限制能力,有呈现以确定的具体方法是在最后一个字符串变更操作导致的实际数据截断(此方法只是返回internall标志,表示截断事件)
// Constrcation, assertion OR appending strs can cause data truncation
// due to the strictly limited size of the internal buffer
// in case of the incoming data truncation occures appropriated flag will be set
// AND this func. will return true
// data truncation indication flag CAN be reseted by some operations
bool truncated() const throw() {
return truncated_;
}
性能调整
存储器池大小自动 对准 到64位的字的大小(如大多数现代处理器是64):
// Based on the the 'MaxLen', auto adjusted, to have a 8 byte alignment
static const auto BUF_SIZE =
MaxLen + 1U + (((MaxLen + 1U) % 8U) (8U - (MaxLen + 1U) % 8U) : 0U);
(通过IS的可能会更好,将其调整到自然的指针大小-的sizeof(的std :: uintptr_t形式))
这里的一个优化方法是提供的具体例的特定处理,例如一个比较运算符 使用具有字符数组到comapre类实例(持ÇSTR)可以在已知的阵列大小受益
// 'str' SHOULD contain the POD C str.
// [!] More efficient then 'operator==(POD C str.)' (coze providing array size),
// BUT less effective, then 'operator==(const TStorageType& str)' [!]
template<const size_t ArrayElemCount>
bool operator==(const TElemType (&str)[ArrayElemCount]) const throw() {
if (str == data_) return true;
// Probably points to the substr. of the str. contatining in 'data_'
if (checkAddrIfInternal(str)) return false;
if (ArrayElemCount < (length_ + 1U)) return false; // optimization
const auto thisStrMemChunkSize = sizeof(*data_) * (length_ + 1U); // in bytes
return isEqualMemD<>(data_, str, thisStrMemChunkSize);
}
(但它看起来像按预期它不工作,因为,至少在我的MS VS 2013社区更新5,这是simlpy不叫)。
这里的比较是由定制执行 isEqualMemD 从功能 MemUtils模块
复制代码
// As 'memcmp' by default (http://www.cplusplus.com/reference/cstring/memcmp/)
template<const bool SignedCmpChunk = false>
// 'memSize' is in bytes
// D - Dispatcher
// (uses either 64 OR 32 bit chunks, depending on the CPU type, to better fit the register size)
// [!] Faster then 'memCmp<>' OR 'memcmp', use instead of 'isEqualMem' [!]
bool isEqualMemD(const void* const mem1, const void* const mem2, const size_t memSize) throw() {
typedef const typename IntegralTypeBySize<8U, SignedCmpChunk>::Type T64Bit;
typedef const typename IntegralTypeBySize<4U, SignedCmpChunk>::Type T32Bit;
typedef const typename IntegralTypeBySize<1U, SignedCmpChunk>::Type T8Bit;
if (memSize < 8U) {
return !memcmp(mem1, mem2, memSize);
}
switch (CPUInfo::INSTANCE.is64BitCPU) {
case true: // 64 bit
assert(memSize >= 8U);
if (!isEqualMem<8U, SignedCmpChunk>(mem1, mem2, memSize / 8U)) return false;
// Check the remain (NOT fitted) bytes; sizeof(char) == 1
return *(reinterpret_cast<T64Bit*>(static_cast<T8Bit*>(mem1) + memSize - 8U)) ==
*(reinterpret_cast<T64Bit*>(static_cast<T8Bit*>(mem2) + memSize - 8U));
default: // 32 bit
assert(memSize >= 4U);
if (!isEqualMem<4U, SignedCmpChunk>(mem1, mem2, memSize / 4U)) return false;
return *(reinterpret_cast<T32Bit*>(static_cast<T8Bit*>(mem1) + memSize - 4U)) ==
*(reinterpret_cast<T32Bit*>(static_cast<T8Bit*>(mem2) + memSize - 4U));
}
}
这个功能仅仅是一个调度程序,它调用基于CPU类型的实际比较函数(受益于CPU寄存器的大小)
// [!] Does NOT checks an incoming args. on validity [!]
// Use this when the fact itself of a difference of the two memory chunks is meaningfull,
// NOT the actual difference value
// [!] Works a bit faster then 'memcmp' [!]
bool isEqualMem(const void* const mem1, const void* const mem2, const size_t iterCount) throw() {
typedef typename IntegralTypeBySize<CmpChunkSize, SignedCmpChunk>::Type TCmpChunkType;
if (mem1 == mem2) return true; // optimization
auto mem1re = static_cast<const TCmpChunkType*>(mem1); // reinterpreted
auto mem2re = static_cast<const TCmpChunkType*>(mem2);
const auto end = mem1re + iterCount;
while (mem1re < end) {
if (*mem1re != *mem2re) return false;
++mem1re, ++mem2re;
}
return true;
}
在那里当前CPU是X32或x64的检测是由执行 HardwareUtils模块
复制代码
#ifndef HardwareUtilsH
#define HardwareUtilsH
#ifdef _MSC_VER
#include <cstring>
#include <intrin.h> // Microsoft Specific
#elif __GNUC__
#include <cpuid.h> // GCC
#endif
class CPUInfo {
public:
// Static singleton (static init. is a thread safe in C++11)
static const CPUInfo INSTANCE;
const bool is64BitCPU = false;
private:
CPUInfo() throw()
: is64BitCPU(findIs64BitCPU())
{}
~CPUInfo() = default;
CPUInfo(const CPUInfo&) throw() = delete;
CPUInfo(CPUInfo&&) throw() = delete;
CPUInfo& operator=(const CPUInfo&) throw() = delete;
CPUInfo& operator=(CPUInfo&&) throw() = delete;
/* Reference:
http://stackoverflow.com/questions/12212385/detect-if-the-processor-is-64-bit-under-32-bit-os
https://en.wikipedia.org/wiki/CPUID
https://en.wikipedia.org/wiki/Long_mode
https://msdn.microsoft.com/en-us/library/hskdteyh(v=vs.120).aspx
https://msdn.microsoft.com/en-us/library/windows/desktop/ms684139(v=vs.85).aspx
http://stackoverflow.com/questions/14266772/how-do-i-call-cpuid-in-linux
*/
// HINT: Better rewrite this using an assembly
// (see examples: https://en.wikipedia.org/wiki/CPUID#CPUID_usage_from_high-level_languages)
static bool findIs64BitCPU() throw() {
static const auto GET_MAX_CMD_SUPPORTED = 0x80000000U; // 2 147 483 648
unsigned int cpuInfo[4U] = {0}; // from EAX, EBX, ECX, and EDX
#ifdef _MSC_VER
auto const cpuInfoRe = reinterpret_cast<int*>(cpuInfo); // reinterpreted
__cpuid(cpuInfoRe, GET_MAX_CMD_SUPPORTED);
// Max. value of 'function_id' supported for extended functions
const auto maxFuncIDSupported = *cpuInfo; // at 'EAX'
#elif __GNUC__
// 'ext' SHOULD be 0x8000000 to return highest supported value for extended 'cpuid' information
// Returns 0 if 'cpuid' is not supported or whatever 'cpuid' returns in EAX register
const auto maxFuncIDSupported = __get_cpuid_max(GET_MAX_CMD_SUPPORTED, nullptr);
#else
static_assert(false, "Unsupported complier"); // __BORLANDC__, __MINGW32__
#endif
// Get Extended Processor Info and Feature Bits
static const auto GET_EXTENDED_INFO = 0x80000001U; // 2 147 483 649
// If does NOT supports extended flags
if (maxFuncIDSupported < GET_EXTENDED_INFO) return false;
#ifdef _MSC_VER
memset(cpuInfo, 0, sizeof(cpuInfo));
__cpuid(cpuInfoRe, GET_EXTENDED_INFO);
#elif __GNUC__
// Checks if 'cpuid' is supported and returns 1 for valid cpuid information or
// 0 for unsupported cpuid level
if (!__get_cpuid(GET_EXTENDED_INFO, cpuInfo, cpuInfo + 1U, cpuInfo + 2U, cpuInfo + 3U))
return false;
#endif
//' LM' (Long Mode) flag for AMD / 'EM64T' for Intel
static const auto LONG_MODE_BIT = 536870912U; // 2 pow 29: 29-th bit
// Check if bit is signaled
return 0U != (LONG_MODE_BIT & cpuInfo[3U]); // from EDX (cpuInfo[3U])
}
};
#endif // HardwareUtilsH
getFNV1aHash 从功能 HashUtils模块),它允许对字符串实例存储在 有效的搜索数据结构 的 常量。分期时间的项目的查找。但类还支持智能哈希高速缓存 -如果存储称为哈希码值,并将其(如果仍然相关),而不是recalcuating它
//// [!] Hashing algo. SHOULD never be changed at the runtime (must be deterministic) [!]
// Uses FNV-1a algorithm (ONLY for the one byte chars - char / unsigned char!!)
size_t hash() const throw() {
static_assert(1U == sizeof(TElemType), "'TElemType' SHOULD be 1 byte long!");
if (modified_) { // recalc. rather then returning cached value
hash_ = MathUtils::getFNV1aHash(data_);
modified_ = false;
}
return hash_;
}
比较运算符 还对散列缓存益:如果比较某些兼容的类型,这使得散列码计算与缓存的两个存储实例,假定哈希码已经计算(具有相同的散列算法),并仍然相关的两个实例-如果散列码是不同的则实例不相等(那些提出比较 复杂不变而不是线性)
复制代码
// Compatible with the ANY storage class which has 'TElemType' as an elem. type
// AND provides the null-terminated str. by the public const member 'c_str'
// AND returning actual str. len. with the public const member 'length'
// (like std::string, StaticallyBufferedStringLight<ANY SIZE> etc)
// [!] The most effective type of comparing strs is
// comparing a one 'StaticallyBufferedStringLight' to another (coze providing hash) [!]
template<class TStorageType>
bool operator==(const TStorageType& str) const throw() {
if (str.length() != length()) return false;
// Using hash code. algo. ID to identify if the same algo. is used by the 'str' instance
// OPTIMIZATION HINT: use C++14 'constexpr' here
static const auto SAME_HASHING_ = (hashAlgoID() == hashAlgoID::ExecIfPresent(str));
if (SAME_HASHING_) {
const auto thisHash = getHashIfKnown(); // ONLY if already calculated
if (thisHash) { // if this hash is relevant
// If 'TStorageType' provides hash code
// AND hash code is ALREADY calculated (cached) AND relevant
// for the BOTH compared objects - if codes does NOT equal ->
// objects is clearly diffirent (return false)
// Called ONLY if exists (if NOT - called surrogate which is ALWAYS return zero)
const auto otherHash = getHashIfKnown::ExecIfPresent(str);
// REMEMBER that hash code equivalence does NOT actually means that object are equal
// due to the non-nill collison probabilty
if (otherHash && otherHash != thisHash) return false; // if other hash is known AND relevant
}
}
static const auto SAME_CHAR_TYPE_ = // remove cv and ref.
std::is_same<typename std::decay<decltype(*c_str())>::type,
typename std::decay<decltype(*str.c_str())>::type>::value;
switch (SAME_CHAR_TYPE_) {
case true: return isEqualMemD<>(data_, str.c_str(), sizeof(*data_) * length());
// Diff. types: call 'operator==(const TOtherElemType* const str)'
default: return *this == str.c_str();
}
}
hashAlgoID 和 getHashIfKnown 这里使用的辅助功能,它们是很好的自我解释的
// Returns unique ID of the hashing algo. used to calculate
// a value returned by the 'hash' AND 'getHashIfKnown' routines
// [!] SHOULD never return zero [!]
// Define AND use this if you planning to compare this instance with the other instances
// which using the same hash code calculation algorithm [OPTIMIZATION]
// OPTIMIZATION HINT : use C++14 'constexpr' here
static size_t hashAlgoID() throw() {
static const size_t ID_ = 'F' + 'N' + 'V' + '-' + '1' + 'a';
return ID_;
}
// NEVER recalculates hash
// Returns zero if actual hash is unknown OR if str. is empty
size_t getHashIfKnown() const throw() {
return modified_ size_t() : hash_;
}
他们都使用的是实际调用 ExecIfPresent成语
EXEC_MEMBER_FUNC_IF_PRESENT(getHashIfKnown, size_t())
EXEC_MEMBER_FUNC_IF_PRESENT(hashAlgoID, size_t())
因此,这是存储类型不支持这种机制(如非标准的std :: string的)也可以与此类一起使用,这些使得它更加灵活,有弹性。
一个相等比较运算符可以对散列码缓存也有利于 如果 (且仅仅如果)证明,哈希码生成算法生成的方式的散列值,该值较大(在计散列对比)字符串总是较大太
复制代码
// [!] The most effective type of comparing strs is
// comparing a one 'StaticallyBufferedStringLight' to another (coze providing hash) [!]
// 'TStorageType' SHOULD provide POD C str. with it's 'data' function
template<class TStorageType>
bool operator<(const TStorageType& str) const throw() {
// Using hash code. algo. ID to identify if the same algo. is used by the 'str' instance
// OPTIMIZATION HINT: use C++14 'constexpr' here
static const auto SAME_HASHING_ = (hashAlgoID() == hashAlgoID::ExecIfPresent(str));
// If proved that the hash code of a larger str. is larger -
// we can just check the hash code here [OPTIMIZATION]
// (ONLY if the hash code algo. is ALWAYS generates a lager hash for a larger str., FNV-1a is NOT)
if (SAME_HASHING_ && HashCodeChecker::INSTANCE.hashOfLargerStrLarger) {
// Get hash ONLY if already known [OPTIMIZATION]
const auto thisHashCached = getHashIfKnown(), otherHashCached = str.getHashIfKnown();
if (thisHashCached && otherHashCached && (thisHashCached != otherHashCached)) {
// Equal caches does NOT necessary means the strs is actually equal,
// due to collison probability
return thisHashCached < otherHashCached;
}
}
static const auto SAME_CHAR_TYPE_ = // remove cv and ref.
std::is_same<typename std::decay<decltype(*c_str())>::type,
typename std::decay<decltype(*str.c_str())>::type>::value;
switch (SAME_CHAR_TYPE_) {
case true:
if (static_cast<const void*>(data_) == static_cast<const void*>(str.data())) return false;
return 0 > memcmp(data(), str.data(),
sizeof(*data_) * (std::min<>(length(), str.length()) + 1U));
default:
return *this < str.data(); // diff. types: call 'operator<(const TOtherElemType* const str)'
}
}
FNV-1A算 法,通过,并不能由一个自动化测试模块作为证明satisfys这个要求 HashCodeChecker
复制代码
#include "StaticallyBufferedStringLight.h"
struct HashCodeChecker::HashChecker {
size_t operator()(const std::string& str) const throw() {
if (!COLLECT_STATS && !NEXT_HASH_LARGER_OR_EQ) return 0U; // skip [OPTIMIZATION]
STR = str;
const auto currHash = STR.hash();
const auto nextLargerOrEq = (currHash >= PREV_HASH);
nextLargerOrEq ++STATS[1U] : ++*STATS;
NEXT_HASH_LARGER_OR_EQ &= nextLargerOrEq;
PREV_HASH = currHash;
return currHash;
}
static bool COLLECT_STATS; // will be initially false as a static
// First - next lower count (NOT OK!), second - next larger count (OK); both zero at the start
static size_t STATS[2U]; // first: NOT larger, second: next larger count
static size_t PREV_HASH; // will be initially zero as a static
static bool NEXT_HASH_LARGER_OR_EQ; // initially true!!
static StaticallyBufferedStringLight<char, 7U> STR;
};
bool HashCodeChecker::HashChecker::COLLECT_STATS;
size_t HashCodeChecker::HashChecker::STATS[2U];
size_t HashCodeChecker::HashChecker::PREV_HASH;
bool HashCodeChecker::HashChecker::NEXT_HASH_LARGER_OR_EQ = true;
decltype(HashCodeChecker::HashChecker::STR) HashCodeChecker::HashChecker::STR;
template <const bool SkipStatistics>
bool HashCodeChecker::ishashOfLargerStrLarger() throw() {
//// Test A
static const auto MAX_LEN_ = 55U;
static_assert('A' + MAX_LEN_ < 128, "Incorrect max. len.");
StaticallyBufferedStringLight<char, MAX_LEN_> str;
decltype(str.hash()) prevHash = str.hash(), nowHash = 0U;
auto currChar = 'A'; // from 'A' to 'A'+MAX_LEN_
auto nextHashLargerOrEqCount = 0U, nextHashLowerCount = 0U;
for (auto charIdx = 0U; charIdx < str.max_size(); ++charIdx) {
str += currChar;
++currChar;
nowHash = str.hash();
nowHash >= prevHash ++nextHashLargerOrEqCount : ++nextHashLowerCount;
if (SkipStatistics && nextHashLowerCount) return false;
prevHash = nowHash;
}
//// Test B
char strBuf[4U] = {0};
HashTester::Params<std::extent<decltype(strBuf)>::value> params(strBuf);
const auto result = HashTester::createAndTestCharSeq<HashChecker>(params, false);
return !nextHashLowerCount && result && HashChecker::NEXT_HASH_LARGER_OR_EQ;
}
#ifdef _MSC_VER
// GCC might NOT build with this, while MS VS 2013 will NOT build withOUT this
const HashCodeChecker HashCodeChecker::INSTANCE;
#endif
(本moduIe使用 HashTester 模块)。
还有一个具体的 追加 提出方法,它是用来做优化的(因为它跳过双缓冲复制/ 临时对象的创建和销毁 / 堆内存的使用情况,不像非标准的std :: to_string,例如)串联一个字符串表示的 数
复制代码
// Adds a WHOLE number in a str. representation
// (be carefull here, do NOT miss with the 'operator+=(const TElemType symb)')
template<typename TValueType,
class = typename // remove from the overload resolution to avoid an ambiguity
std::enable_if<std::is_arithmetic<TValueType>::value &&
!std::is_pointer<TValueType>::value && // 'std::nullptr_t' is OK
!std::is_same<TValueType, TElemType>::value>::type>
StaticallyBufferedStringLight& append(const TValueType value) throw() {
const auto spaceLeft = std::extent<decltype(data_)>::value - length_;
if (spaceLeft < 2U) { // NO actual space left (1 for the str. terminator)
truncated_ = true;
return *this;
}
const char* mask = "";
auto returnFlag = false; // true if return immediately
auto getMask = [&]() throw() {
typedef typename TypeTag<decltype(value)>::TypeTags_ Tags;
switch (TYPE_TAG(value)) {
// OPTIMIZATION thoughts: reduce the mask count
// use 'if std::is_floatinng<decltype(value)>' for two mask types - float|integral
default: assert(false); // unidentified type
case Tags::NULLPTR: returnFlag = true; break;
case Tags::BOOL: mask = value "true" : "false"; break;
case Tags::SIGNED_CHAR: mask = "%hhi"; break;
case Tags::SIGNED_SHORT_INT: mask = "%hi"; break;
case Tags::SIGNED_INT:
case Tags::WCHAR: // signedness of wchar_t is unspecified
mask = "%i"; break;
case Tags::SIGNED_LONG_INT: mask = "%li"; break;
case Tags::SIGNED_LONG_LONG_INT: mask = "%lli"; break;
case Tags::UNSIGNED_CHAR: mask = "%hhu"; break;
case Tags::UNSIGNED_SHORT_INT: mask = "%hu"; break;
case Tags::UNSIGNED_INT: mask = "%u"; break;
case Tags::UNSIGNED_LONG_INT: mask = "%lu"; break;
case Tags::UNSIGNED_LONG_LONG_INT: mask = "%llu"; break;
case Tags::FLOAT:
case Tags::DOUBLE:
mask = "%f"; break;
case Tags::LONG_DOUBLE: mask = "%Lf";
}
};
getMask();
if (returnFlag) return *this;
#ifdef _MSC_VER // MS VS specific
// Number of characters stored in buffer, not counting the terminating null character
auto count = _snprintf_s(data_ + length_, spaceLeft, _TRUNCATE, mask, value);
if (count < 0) { // if NOT enough space left
count = spaceLeft - 1U;
truncated_ = true;
}
#else
// Number of characters that properly SHOULD have been written (except terminating null character)
auto count = snprintf(data_ + length_, spaceLeft, mask, value);
if (count < 0) {
data_[length_] = '\0'; // ensure NO actual changes
return *this; // encoding error
}
if ((count + 1U) > spaceLeft) { // +1 for the str. terminator
count = spaceLeft - 1U;
truncated_ = true;
}
#endif
length_ += count;
modified_ = true;
return *this;
}
速度对比
而现在真正的考验!
(ALL中进行的测试版本与模式ALL优化转向上,内置的32倍的MS VS社区2013更新5, 拼命地跑在我联想的IdeaPad S400的x64 下的笔记本电脑64赢8.1)
1)级联速度测试
该测试执行许多(400〜000)最小(由一个单一的字符)串联字符串实例。这是一个很好的情况下,标准::字符串(如ONY的一小百分之串联会导致情况长度将变大,那么当前的容量要求这样做了重新分配,而这%将甚至可能在时间减少,依赖于实际的字符串实现),最坏的情况下ç海峡。(因为它要求以确定[与线性 复杂性操作的一个实际此外,这导致了之前]的字符串长度的时间复杂度的一个增长算术级数 withing每个呼叫)和不-护理情况下的静态海峡。
标准::字符串:
- 最佳: 所有需要的空间被 预先分配 的前 CONCAT。
- 最差:另外一个字符串,其长度是生长在的 几何级数 以这样的方式,每个除了将需要做 重新分配
Ç海峡:
- 最好的:一个单独的除空字符串
- 最糟糕的:许多最小 串联 到长初始的字符串
静态STR:所有案例都是平等的
测试代码:
复制代码
static const auto STR_BUF_SIZE_ = 440U * 1024U;
CStr<STR_BUF_SIZE_ - 1U> cstr___1_;
StaticallyBufferedStringLight<char, STR_BUF_SIZE_ - 1U> static_str___1_;
std::string dynamic_str___1_;
cstr___1_.clear();
std::cout << cstr___1_.strBuf; // to force the compiler to generate the actual code
const volatile auto cstr_test_time_ =
TestConcat(cstr___1_, STR_BUF_SIZE_ - 1U).count();
cstr___1_.clear();
std::cout << cstr___1_.strBuf; // to force the compiler to generate the actual code
static_str___1_.clear();
std::cout << static_str___1_; // to force the compiler to generate the actual code
const volatile auto static_str_test_time_ =
TestConcat(static_str___1_, STR_BUF_SIZE_ - 1U).count();
cstr___1_.clear();
std::cout << cstr___1_.strBuf; // to force the compiler to generate the actual code
dynamic_str___1_.clear();
std::cout << dynamic_str___1_; // to force the compiler to generate the actual code
const volatile auto dynamic_str_test_time_ =
TestConcat(dynamic_str___1_, STR_BUF_SIZE_ - 1U).count();
cstr___1_.clear();
std::cout << cstr___1_.strBuf; // to force the compiler to generate the actual code
std::cout << "static str: " << static_str_test_time_ << std::endl;
std::cout << "dynamic str: " << dynamic_str_test_time_ << std::endl;
std::cout << "cstr: " << cstr_test_time_ << std::endl;
std::cout << "\nStatic str.: 1.0, dynamic str.: "
<< static_cast<double>(dynamic_str_test_time_) / static_str_test_time_
<< ", POD C str.: "
<< static_cast<double>(cstr_test_time_) / static_str_test_time_ << std::endl;
template <class TStrType>
auto TestConcat(TStrType& str, const size_t maxLen) throw()
-> decltype(std::chrono::system_clock::now() - std::chrono::system_clock::now())
{
static const auto MIN_CHAR_ = 'a';
static const auto MAX_CHAR_ = 'z';
static_assert(MIN_CHAR_ < MAX_CHAR_, "Invalid chars");
std::default_random_engine gen;
std::uniform_int_distribution<int> distr(MIN_CHAR_, MAX_CHAR_);
char strToAdd[2U] = {0};
str.clear();
const auto startTime = std::chrono::high_resolution_clock::now();
for (size_t charIdx = 0U; charIdx < maxLen; ++charIdx) {
*strToAdd = distr(gen); // constant complexity
str += strToAdd; // linear to const complexity
}
const auto endTime = std::chrono::high_resolution_clock::now();
return endTime - startTime;
}
template <const size_t MaxLen>
struct CStr {
CStr() throw() {
clear();
}
void clear() throw() {
*strBuf = '\0';
}
void operator+=(const char* const str) throw() {
strcat(strBuf, str);
}
char strBuf[MaxLen + 1U];
};
结果:

2)内存比较例程的速度测试
本次测试涉及到非标准的C测试速度memcmp / STRCMP ,并从我的自定义功能比较 MemUtils 模块。
测试代码:
复制代码
const auto SIZE_ = 1024U * 1024U * 8U;
auto mem1 = new char[SIZE_];
memset(mem1, 200, SIZE_ - 1U);
auto mem2 = new char[SIZE_];
memset(mem2, 200, SIZE_ - 1U);
mem1[SIZE_ - 1U] = '\0';
mem2[SIZE_ - 1U] = '\0';
// (64 bit OS, 64 bit CPU, 32 bit application)
decltype(std::chrono::system_clock::now()) time1, time2;
static const auto COUNT_001_ = 7U;
static const auto TEST_COUNT_001_ = 40U;
decltype((time2 - time1).count()) counts[COUNT_001_] = {0};
auto memCmp_faster_then_memcmp_count = size_t();
auto memCmp_faster_then_quickCmp = size_t();
unsigned long long avg[COUNT_001_] = {0};
const auto iterCount_1_ = 40U;
for (size_t idx = 0U; idx < iterCount_1_; ++idx) {
time1 = std::chrono::system_clock::now();
volatile long long int r0 = 0LL;
for (size_t testIdx = size_t(); testIdx < TEST_COUNT_001_; ++testIdx) {
// 'strCmp<>' with 4U works MUCH faster, then with the 8U
r0 = strCmp<>(mem1, mem2);
}
time2 = std::chrono::system_clock::now();
*counts = (time2 - time1).count();
*avg += *counts;
time1 = std::chrono::system_clock::now();
volatile long long int r1 = 0LL;
for (size_t testIdx = size_t(); testIdx < TEST_COUNT_001_; ++testIdx) {
// 'quickCmp' looks like with 8U works faster, then with the 4U
// (BUT we can't use 8U AND this func. is NOT used)
r1 = quickCmp(mem1, mem2, SIZE_);
}
time2 = std::chrono::system_clock::now();
counts[1] = (time2 - time1).count();
avg[1U] += counts[1];
time1 = std::chrono::system_clock::now();
volatile long long int r2 = 0LL;
for (size_t testIdx = size_t(); testIdx < TEST_COUNT_001_; ++testIdx) {
r2 = memcmp(mem1, mem2, SIZE_);
}
time2 = std::chrono::system_clock::now();
counts[2] = (time2 - time1).count();
avg[2U] += counts[2];
time1 = std::chrono::system_clock::now();
volatile long long int r3 = 0LL;
for (size_t testIdx = size_t(); testIdx < TEST_COUNT_001_; ++testIdx) {
r3 = strcmp(mem1, mem2);
}
time2 = std::chrono::system_clock::now();
counts[3] = (time2 - time1).count();
avg[3U] += counts[3];
time1 = std::chrono::system_clock::now();
volatile long long int r4 = 0LL;
const auto count_1_ = SIZE_ / sizeof(std::uintptr_t);
for (size_t testIdx = size_t(); testIdx < TEST_COUNT_001_; ++testIdx) {
// 'memCmp' with 8U works faster, then with 4U (BUT we can't do that)
r4 = memCmp<>(mem1, mem2, count_1_);
}
time2 = std::chrono::system_clock::now();
counts[4] = (time2 - time1).count();
avg[4U] += counts[4];
time1 = std::chrono::system_clock::now();
volatile bool r5 = false;
for (size_t testIdx = size_t(); testIdx < TEST_COUNT_001_; ++testIdx) {
r5 = isEqualMemD(mem1, mem2, SIZE_);
}
time2 = std::chrono::system_clock::now();
counts[5] = (time2 - time1).count();
avg[5U] += counts[5];
time1 = std::chrono::system_clock::now();
volatile bool r6 = false;
const auto count_02_ = SIZE_ / 8U;
for (size_t testIdx = size_t(); testIdx < TEST_COUNT_001_; ++testIdx) {
r6 = isEqualMem<8U>(mem1, mem2, count_02_);
}
time2 = std::chrono::system_clock::now();
counts[6] = (time2 - time1).count();
avg[6U] += counts[6];
std::cout << "\n";
std::cout << "count6 - isEqualMem<8U> : " << counts[6] << "\n";
std::cout << "count5 - isEqualMemD : " << counts[5] << "\n";
std::cout << "count4 - memCmp<> : " << counts[4] << "\n";
std::cout << "count3 - strcmp : " << counts[3] << "\n";
std::cout << "count2 - memcmp : " << counts[2] << "\n";
std::cout << "count1 - quickCmp : " << counts[1] << "\n";
std::cout << "count0 - strCmp<> : " << *counts << "\n";
std::cout << "\n" << static_cast<double>(counts[3]) / counts[1] << "\n";
assert(r1 == r2);
if (counts[4] < counts[2]) ++memCmp_faster_then_memcmp_count;
if (counts[4] < counts[1]) ++memCmp_faster_then_quickCmp;
}
std::cout << "\nmemCmp_faster_then_memcmp_count: "
<< memCmp_faster_then_memcmp_count << " / "
<< iterCount_1_ << std::endl;
std::cout << "memCmp_faster_then_quickCmp: "
<< memCmp_faster_then_quickCmp << " / "
<< iterCount_1_ << std::endl << std::endl;
const char* const names_001_[]
= {"strCmp<> ",
"quickCmp ",
"memcmp ",
"strcmp ",
"memCmp<> ",
"isEqualMemD ",
"isEqualMem<8U> "};
auto idx_0001_ = 0U;
for (volatile auto& currAvg : avg) {
currAvg /= iterCount_1_;
std::cout << "avg " << names_001_[idx_0001_] << " - #" << idx_0001_ << ": " << currAvg << std::endl;
++idx_0001_;
}
delete[] mem1, delete[] mem2;
结果:
静态海峡。采用最合适的(不总是最快)功能: STRCMP <> , isEqualMemD <> , memcmp。
静态海峡。使用 isEqualMemD <>而不是 memcmp 如果可能的话,因为它的速度更快, STRCMP <> 而不是strcmp的 ,因为它能够比较多个字符类型和 memcmp 而不是 STRCMP <> 如果可能的话,因为它是速度更快。
通过这个页面说,非标准memcmp 功能 对固有形式的所有架构和我编译我的测试案例“ /爱' 编译器选项,测试表明,自 isEqualMemD <> 略快(这可能是should't)。
3) 关系比较速度测试
测试' 小于'运营商的速度。
测试代码:
复制代码
const decltype(s_str_01_) s_str_02_ = static_chars_01_;
const decltype(dstr_01_) dstr_02_ = static_chars_01_;
volatile auto result__01_ = false;
time1 = std::chrono::system_clock::now();
for (size_t testIdx = size_t(); testIdx < 100000U; ++testIdx) {
result__01_ = s_str_01_ < s_str_02_;
}
time2 = std::chrono::system_clock::now();
counts[1] = (time2 - time1).count();
time1 = std::chrono::system_clock::now();
for (size_t testIdx = size_t(); testIdx < 100000U; ++testIdx) {
result__01_ = dstr_01_ < dstr_02_;
}
time2 = std::chrono::system_clock::now();
counts[2] = (time2 - time1).count();
time1 = std::chrono::system_clock::now();
for (size_t testIdx = size_t(); testIdx < 100000U; ++testIdx) {
result__01_ = strcmp(s_str_01_.c_str(), s_str_02_.c_str()) == 0;
}
time2 = std::chrono::system_clock::now();
counts[3] = (time2 - time1).count();
volatile auto diff = static_cast<double>(counts[2]) / counts[1];
std::cout << "\nStatic str. 'operator<' " << diff << " times faster then the dynamic one\n";
diff = static_cast<double>(counts[3]) / counts[1];
std::cout << " and " << diff << " times faster then the 'strcmp'\n";
结果:

4)质量分配/释放速度测试
说明了为什么在概念实际上诞生 
首先, PerformanceTester 模块,用来做测试:
复制代码
#ifndef PerformanceTesterH
#define PerformanceTesterH
#include <chrono>
#include <iostream>
class PerformanceTester {
public:
struct TestResults {
typedef decltype(std::chrono::system_clock::now()) TTimePoint;
typedef decltype((TTimePoint() - TTimePoint()).count()) TTimeCount;
void clear() throw() {
time1 = TTimeCount(), time2 = TTimeCount();
}
TTimeCount time1 = TTimeCount(), time2 = TTimeCount();
};
// Returns diff. (2/1)
template <class TFunctor1, class TFunctor2, const bool onScreen = true>
static double test(TFunctor1& subj1, TFunctor2& subj2,
const size_t testCount, TestResults& results)
{
results.clear();
if (!testCount) return 0.0;
auto time1 = TestResults::TTimePoint(), time2 = TestResults::TTimePoint();
auto testIdx = size_t();
auto testSubj = [&](const bool isSecondSubj) throw() {
time1 = std::chrono::system_clock::now();
for (testIdx = size_t(); testIdx < testCount; ++testIdx) {
switch (isSecondSubj) {
case true: subj2(); break;
default: subj1(); // false
}
}
time2 = std::chrono::system_clock::now();
return (time2 - time1).count();
};
results.time1 = testSubj(false);
results.time2 = testSubj(true);
const auto diff = static_cast<double>(results.time2) / results.time1;
if (onScreen) {
auto const potfix = (diff < 1.0) "faster" : "slower";
const auto diffReinterpreted = (diff < 1.0) (1.0 / diff) : diff;
std::cout << "\nSecond is " << diffReinterpreted << " times " << potfix << std::endl;
}
return diff;
}
};
#endif // PerformanceTesterH
测试代码:
struct Funct1__ {
volatile int operator()() throw() {
volatile StaticallyBufferedStringLight<> str;
return 0;
}
} funct1__;
struct Funct2__ {
volatile int operator()() throw() {
std::string str;
str.reserve(127U);
return 0;
}
} funct2__;
PerformanceTester::TestResults results1;
PerformanceTester::test(funct1__, funct2__, 9999999U, results1);
结果:

5)质量 相等比较速度测试
测试' 不等于'运营商 的速度在静态str的情况下。哈希码已经计算。
测试代码(差异接近尾声符号) :
复制代码
static auto const STR1
= "cam834mht8xth,a4xh387th,txh87c347837 g387go4 4w78t g34 3g7rgo bvgq7 tgq3874g478g8g oebgbg8 b"
"cwmc8htcw,o7845mt754cm8w4gcm8w4gc78w4gcw4cw4yc4c4xn34x63gc7sch74s4h5mc7h7cn34xm7xg78gxm7384x";
static auto const STR2
= "cam834mht8xth,a4xh387th,txh87c347837 g387go4 4w78t g34 3g7rgo bvgq7 tgq3874g478g8g oebgbg8 b"
"cwmc8htcw,o7845mt754cm8w4gcm8w4gc78w4cw4cw4yc4c4xn34x63gc7sc_74s4h5mc7h7cn34xm7xg78gxm7384x";
struct Funct1__ {
Funct1__() throw() : str1(STR1), str2(STR2) {
//// Prehash
str1.hash();
str2.hash();
}
volatile int operator()() throw() {
volatile auto result = (str1 != str2);
return 0;
}
StaticallyBufferedStringLight<char, 255U> str1;
StaticallyBufferedStringLight<char, 255U> str2;
} funct1__;
struct Funct2__ {
Funct2__() throw() : str1(STR1), str2(STR2) {}
volatile int operator()() throw() {
volatile auto result = (str1 != str2);
return 0;
}
std::string str1;
std::string str2;
} funct2__;
PerformanceTester::TestResults results1;
PerformanceTester::test(funct1__, funct2__, 9999999U, results1);
结果:

同样的测试与第一个差异。符号:

C++教程阅读排行
-

2013-09-18
-
2016-02-22
-
2016-05-24
-
2013-09-18
-
2013-09-18
-
2013-09-18
-

2013-09-18
-
2013-09-18
最新文章
-

2022-03-16
-
2022-03-16
-
C#开发WinForm清空DataGridView控件绑定的数据
2022-03-16
-

C#开发WinForm根据条件改变DataGridView行颜色
2022-03-16
-

2022-03-16
-
2016-05-24
-
2016-02-22
-
2013-09-18
热门源码
