介绍
深度神经网络在诸如图像分类等任务上非常出色。拥有一半像样的GPU的任何人现在都可以轻松获得十年前耗资数百万美元的结果以及整个研究团队。但是,深度神经网络有一个缺点。它们可能非常笨重且缓慢,因此它们并不总是在移动设备上运行良好。幸运的是,Core ML提供了一个解决方案:它使您能够创建在iOS设备上运行良好的苗条模型。
在本系列文章中,我们将向您展示如何以两种方式使用Core ML。首先,您将学习如何将预先训练的图像分类器模型转换为Core ML并在iOS应用中使用它。然后,您将训练自己的机器学习(ML)模型并将其用于制作Not Hotdog应用程序-就像您在HBO的硅谷所见过的那样。
在上一篇文章中,我们准备了我们的开发环境。在这一部分中,我们将训练有素的ONNX图像分类模型转换为Core ML格式。
核心ML和ONNX
Core ML是Apple的框架,允许您将ML模型集成到应用程序中(不仅适用于移动设备和台式机,还适用于手表和Apple TV)。考虑iOS设备上的ML时,建议始终从Core ML开始。该框架非常易于使用,并且支持Apple设备上可用的自定义CPU,GPU和Neural Engine的充分利用。此外,您几乎可以将任何神经网络模型转换为Core ML的本机格式。
如今,很多ML框架正在大量使用,例如TensorFlow,Keras和PyTorch。每个框架都有其自己的格式来保存模型。有一些工具可以将大多数格式直接转换为Core ML。我们将重点介绍开放式神经网络交换(ONNX)格式。ONNX定义了一种通用的文件格式和操作,以使在框架之间切换变得更加容易。
让我们看一下所谓的模型动物园中可用的ONNX模型:
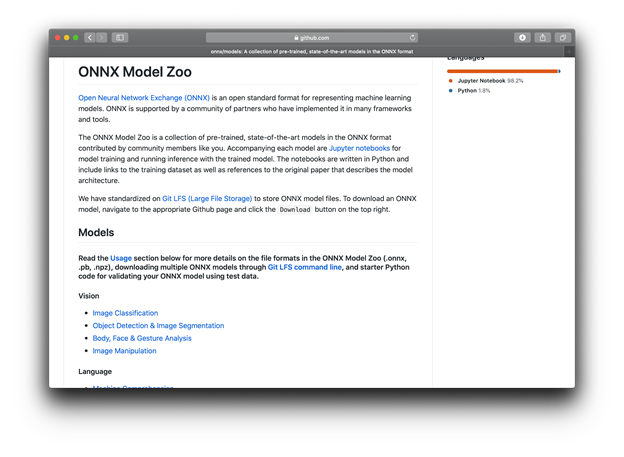
单击“ 视觉”部分“ 图像分类”中的第一个链接。这是它显示的页面:
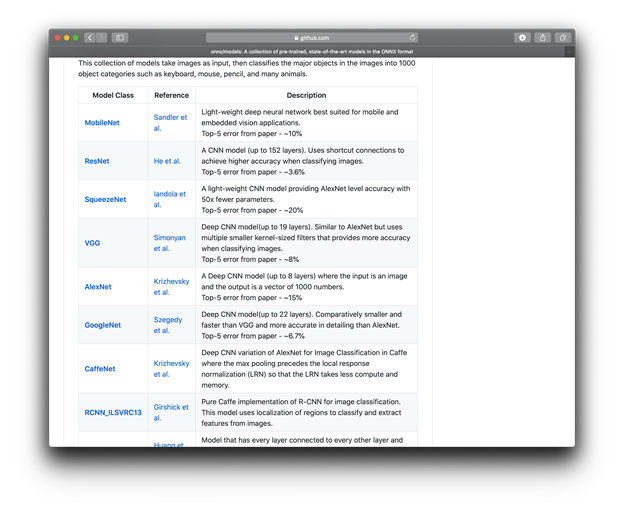
如您所见,有很多模型可供选择。这些模型是使用著名的ImageNet分类数据集进行训练的,该数据集包含1,000个对象类别(例如“键盘”,“圆珠笔”,“蜡烛”,“狼蛛”,“大白鲨”等等……确切地说,是995其他)。
尽管这些模型的体系结构和用于训练它们的框架有所不同,但在模型动物园中,它们似乎都已转换为ONNX。
ResNet是此处可用的最佳模型之一(错误率低至3.6%)。这是我们将用于转换为Core ML的代码。
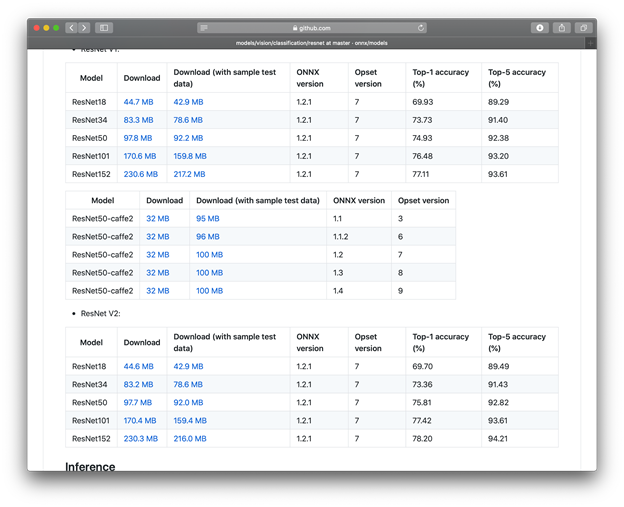
要下载模型,请单击上表中的ResNet链接,然后向下滚动到所需的模型版本。
为了向您展示,使用Core ML,iOS设备可以处理“真实”模型,我们将选择可用的最大(也是最好的)模型- 具有152层的ResNet V2。对于较旧的iOS设备,例如iPhone 6或7,您可能需要尝试使用较小的型号之一,例如ResNet18。
将模型从ONNX转换为Core ML
可以使用Conda环境中安装的coremltools和onnx软件包将几乎所有模型转换为Core ML ,只要该模型使用Core ML支持的操作和层(opset版本)(当前为opset 10及更低版本)即可。
两种类型的模型得到了专门的支持:分类和回归。分类模型将标签分配给输入(例如图像)。回归模型计算给定输入的数值。
我们将重点介绍图像分类模型。
所选的ResNet模型期望什么作为输入?有关详细说明,请参见相应的Zoo模型页面。

如您所见,ResNet模型期望数组中的图片具有以下尺寸:批处理,尺寸通道(红色,绿色和蓝色通道始终为3),高度和宽度。应使用分别为每种颜色定义的平均值和标准偏差值,将数组值缩放到〜[0,1]的范围。
虽然该coremltools库非常灵活,但其内置的图像分类选项无法使我们完全复制原始的预处理步骤。让我们尝试足够接近:
import coremltools as ct
import numpy as np
def resnet_norm_to_scale_bias(mean_rgb, stddev_rgb):
image_scale = 1 / 255. / (sum(stddev_rgb) / 3)
bias_rgb = []
for i in range(3):
bias = -mean_rgb[i] / stddev_rgb[i]
bias_rgb.append(bias)
return image_scale, bias_rgb
# Preprocessing parameters specific for ResNet model
# as defined at: https://github.com/onnx/models/tree/master/vision/
mean_vec = np.array([0.485, 0.456, 0.406])
stddev_vec = np.array([0.229, 0.224, 0.225])
image_scale, (bias_r, bias_g, bias_b) = resnet_norm_to_scale_bias(mean_vec, stddev_vec)
由于标准ResNet过程使用以下公式为图像中的每个像素计算归一化值,因此需要上述转换:
norm_img_data = (img_data/255 - mean) / stddev =
(img_data/255/stddev) - mean/stddev
Core ML期望这样的事情:
norm_img_data = (img_data * image_scale) + bias
ResNet预处理期望stddev每个通道具有不同的(值缩放),但是Core ML默认情况下支持对应image_scale参数的单个值。
由于概括性好的模型不应受到图像色调微小变化的明显影响,因此可以安全地使用image_scale计算出的单个值作为平均值specified stddev_vec:
image_scale = 1 / 255. / (sum(stddev_rgb) / 3)
接下来,让我们bias为每个颜色通道计算。我们结束了一个集预处理参数(image_scale,bias_r,bias_g和bias_b),我们可以在Core ML转换使用。
配备了计算的预处理参数后,您可以运行转换:
model = ct.converters.onnx.convert(
model='./resnet152-v2-7.onnx',
mode='classifier',
class_labels='./labels.txt',
image_input_names=['data'],
preprocessing_args={
'image_scale': image_scale,
'red_bias': bias_r,
'green_bias': bias_g,
'blue_bias': bias_b
},
minimum_ios_deployment_target='13'
)
让我们简要看一下其中的一些参数:
-
mode='classifier'与class_labels='。/ labels.txt'一起使用提供的标签确定分类模式。这将确保模型不仅输出数值,而且还输出最可能检测到的物体的标签。 -
image_input_names= ['data']表示输入数据包含图像。它将允许您直接使用图像,而无需事先转换为Swift中的MultiArray或Python中的NumPy数组。 -
preprocessing_args指定先前计算的像素值归一化参数。 -
minimum_ios_deployment_target设置为13可确保输入和输出结构比旧版本的iOS少混乱。
运行上面的代码后,您可以打印模型摘要:
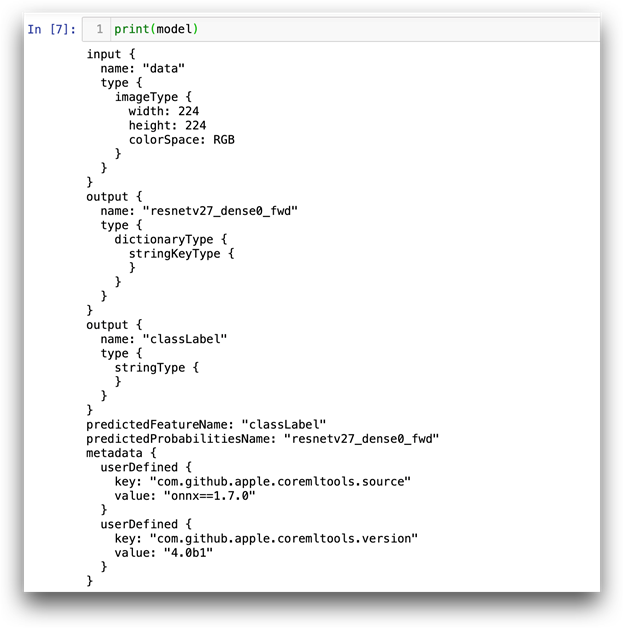
在我们的例子中,模型接受大小为224 x 224像素的RGB图像作为输入,并生成两个输出:
-
classLabel–具有最高模型置信度的对象的标签。 -
resnetv27_dense0_fwd–层输出字典(带有1,000个“ label”:信心对)。此处返回的置信度是原始神经网络输出,而不是概率。可以很容易地将其转换为概率,如代码下载中包含的示例笔记本所示。
运行预测
使用转换后的模型,运行预测是一项简单的任务。让我们使用PIL(枕头)库处理图像,并在代码下载中包含ballpen.jpg图像。

from PIL import Image
image = Image.open('ballpen.jpg')
image = image.resize((224,224))
pred = model.predict(data={"data": image})
print(pred['classLabel'])
预期结果是:
ballpoint, ballpoint pen, ballpen, Biro
随意尝试其他图片。为避免重复转换过程,请保存模型:
model.save('ResNet.mlmodel')
您以后可以加载:
model = ct.models.MLModel('ResNet.mlmodel')
检查代码下载中提供的笔记本,以查看如何从模型输出中获取其他详细信息,例如“前5名”预测候选的概率和标签。
摘要
您已经以Core ML格式转换并保存了ResNet模型。
尽管不同的模型将需要不同的预处理和转换参数,但总体方法将保持不变。
使用模型可以做很多事情,例如添加元数据(模型描述,作者等),添加自定义层(例如最后的softmax来迫使模型返回概率而不是原始网络输出)。我们仅介绍了基础知识,使您可以尝试自己的模型。
将ONNX图像分类模型转换为Core ML 转载https://www.codesocang.com/appboke/51741.html
技术博客阅读排行
-

2016-09-10
-
使用C ++ 11线程支持库创建带有事件循环,消息队列和计时器的辅助线程
2020-09-14
-

快速集成MQTT协议到Android客户端,只需要简单的几个步骤,无需关
2016-09-22
-

2021-01-24
-

2020-12-20
-

2018-04-01
-
2020-08-02
-

2017-01-05
最新文章
-
React Native 启动速度优化――JS 篇【全网最全,值得收藏】
2021-04-19
-
2021-01-24
-
2020-12-20
-

2020-12-19
-

2020-09-14
-
使用C ++ 11线程支持库创建带有事件循环,消息队列和计时器的辅助线程
2020-09-14
-

2020-08-29
-
2020-08-09
热门源码
