CJSONԴ���о��ʼ�
�϶�������CJSONԴ�뿴��Ҳ��һ��ʱ���ˣ��о�һ�������ջ��Ķ࣡���ʺ���һ��C�����������������ֵĿ�ԴԴ�룡cJson.c����ֻ��700���У��������µģ������格���˸о����Ǻܷ����Ķ������ȫ��չ���Ļ�����������ٲ���1100��֮�¡�����Ҳ����һЩǰ���ǵ�cjson�ʼǣ������������������νӴ�CJSON�����൱�а����ģ��������һ��һ��ķ���Դ�룡�����¼һ���Լ���Դ���о�����ıʼǣ�ͬʱҲϣ���Ա�����Ϊ�ο�Ҳ��һ���İ�����
�о�Դ��֮ǰ���Ȼ��Ǹ����CJSON�����Ǹ�ɶ�ģ��������Զ�����Դ���и�����İ���!�����Ǿ�һЩ���ӿ��Դ����˽�һ��what is cjson
CJSON��
����һ:
JSON(JavaScript Object Notation) ��һ�������������ݽ���格ʽ����Ҫ���ڴ������ݡ�JSON ���Խ� JavaScript �����б�ʾ��һ������ת��Ϊ�ַ�����Ȼ��Ϳ����ں���֮�����ɵش�������ַ������������첽Ӧ�ó����н��ַ����� Web �ͻ������ݸ��������˳�������ַ����������е���Ź֣����� JavaScript ���������������� JSON ���Ա�ʾ��"���� / 值��"�����ӵĽṹ�����磬���Ա�ʾ������ӵĶ����������Ǽ���值�ļ��б���JSON������ȫ���������Ե��ı�格ʽ������Ҳʹ������似��C���Լ����ϰ�ߣ�����C,
C++, C#, Java, JavaScript, Perl,Python�ȣ�����Щ����ʹJSON��Ϊ��������ݽ������ԡ��������Ķ��ͱ�д��ͬʱҲ���ڻ������������ɡ�
���Ͷ���
����һ������格ʽ�����ع��ھ����ڴˡ�����һ�ֽ�ͨ���ߣ��������ϰ�Ҫ����һ�������������г�Ҳ��һ�ֽ�ͨ���ߣ�����json���ֽ�ͨ���߸����㣬����ݡ�
��������
����cJSON��ʹ�ã�����Ҫ������ģ��Զ�̷������˷��ص�һ��json���͵�Ŀ¼�ṹ���ͻ��˽��л�ȡ�����н������ѽ���������Ŀ¼����ԭ���Ľṹ��ʾ�ڱ���
��Ȼ���������һЩ������Ȩ���Ļ���CJSON�ٷ����ͣ�����Լ�ֱ���ѣ��ٶȹȸ裡���治���пɹ����صĸ��ֱ�����汾��Դ�룬Ҳ�кܾ���Ľ��ܣ��������������ķ����о�Դ���ˣ���Դ��������SI�����ģ�
#include <string.h>
#include <stdio.h>
#include <math.h>
#include <stdlib.h>
#include <float.h>
#include <limits.h>
#include <ctype.h>
#include "cJSON.h"
static const char *global_ep;
const char *cJSON_GetErrorPtr(void) {return global_ep;}
static int cJSON_strcasecmp(const char *s1,const char *s2)
{
if (!s1) return (s1==s2)0:1;
if (!s2) return 1;
for(; (*s1) == tolower(*s2); ++s1, ++s2)
if(*s1 == 0) return 0;
return tolower(*(const unsigned char *)s1) - tolower(*(const unsigned char *)s2);
}��ͷ�ļ��µĵ�һ�д��뿪ʼ��������һ��ȫ�־�̬�ַ�ָ���������ָ��ָ��һ����������ָ�������Ϊ������.Ȼ������һ�д����ʹ�������ָ�����������global_eq���Կ����������������.c�ļ���ֻ�����������ط���
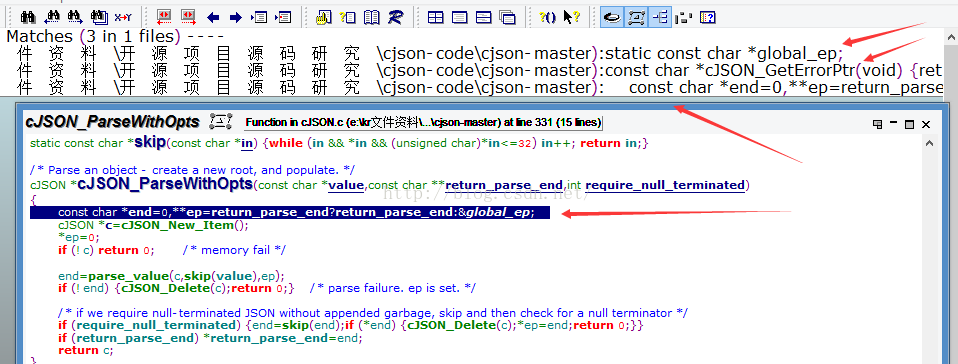
�������������ط�������һ��������ͼ�е��ĸ���ͷ��ָ�ĵط�,
��������:
const char *cJSON_GetErrorPtr(void) {return global_ep;}��
/* If you supply a ptr in return_parse_end and parsing fails, then return_parse_end will contain a pointer to the error. If not, then cJSON_GetErrorPtr() does the job. */
����������Կ���.h�ļ��е�Ӣ��ע�ͣ���������ڹٷ���test.c����һ�ε��ã�
if (!json) {printf("Error before: [%s]\n",cJSON_GetErrorPtr());}����̶�һ�д���ĺ�����ʵ���ǵ�������ַ�������ʧ�ܾͷ��ؽ���ʧ�ܴ��ĵ�ַ��ߵ��ַ�����
�����������з�������Ĵ��룺
������int tolower(int c);
����˵���������� c Ϊ��д��ĸ�ö�Ӧ��Сд��ĸ���ء�
����值������ת�����Сд��ĸ��������ת������c 值���ء�
����˵��
cJSON_strcasecmp()�����Ƚϲ���s1��s2�ַ������Ƚ�ʱ���Զ����Դ�Сд�IJ��졣</span>����值 ������s1��s2�ַ�����ͬ��0��s1���ȴ���s2�����ش���0 ��值��s1 ������С��s2 ������С��0��值.(����������Դ�����Ӧ���Ѿ���������)
static int cJSON_strcasecmp(const char *s1,const char *s2)
{
if (!s1) return (s1==s2)0:1; //if����������ϰ������дif(s1 == NULL) ������������д�о��Ƹ�Ҫ��һ�������
if (!s2) return 1;
for(; (*s1) == tolower(*s2); ++s1, ++s2)
if(*s1 == 0) return 0;
return tolower(*(const unsigned char *)s1) - tolower(*(const unsigned char *)s2);
}���ȶԴ���IJ������Ϸ��Լ�⣬���API�Ĺ��ܾ��DZȽϲ���S1��S2�ַ����������������forѭ�������һ�д���ʱ�Ƚϲ�����Ϊʲô��if(*s1 == 0)��Ϊ���forѭ����һ�����ڣ��ַ�������������'\0'���ѵ�tolower����������������'\0'�ص���0����������֮��������ԭ���Dz�����·���ƣ�

����ASCII�����NULL ����0!
˳�������C���е�strcasecmp��������ôʵ�ֵģ�
int strcasecmp(const char *s1, const char *s2)
{
int c1, c2;
do {
c1 = tolower(*s1++);
c2 = tolower(*s2++);
} while(c1 == c2 && c1 != 0);
return c1 - c2;
}static void *(*cJSON_malloc)(size_t sz) = malloc;//����һ������ָ�벢��ʼ��ָ��malloc���� static void (*cJSON_free)(void *ptr) = free;//ͬ�ϣ�������һ�����������Ĺ��ܣ��±��ᵽ
//��������ַ�������һ�����������µ��ַ���ָ��
static char* cJSON_strdup(const char* str)
{
size_t len;
char* copy;
len = strlen(str) + 1;
if (!(copy = (char*)cJSON_malloc(len))) return 0;
memcpy(copy,str,len);
return copy;
}//Hook�ڴ��������,Ĭ�����롢�ͷ��ڴ溯��malloc��free Ҳ�����Զ��ڴ�����������������ȣ�˳���������Ŀ��������к���ָ�������������ֱ�Ǵ�д���ޣ�������İ�ȫ���ǵ�Ҳ�Ƚ�ȫ��
void cJSON_InitHooks(cJSON_Hooks* hooks)
{
if (!hooks) { /* Reset hooks */ //���hooksΪ�գ�ʹ��Ĭ�ϵ��ڴ����
cJSON_malloc = malloc;
cJSON_free = free;
return;
}
cJSON_malloc = (hooks->malloc_fn)hooks->malloc_fn:malloc;
cJSON_free = (hooks->free_fn)hooks->free_fn:free;
}����˳������cJSON_Hook�ṹ�嶨�壺
typedef struct cJSON_Hooks {
void *(*malloc_fn)(size_t sz);
void (*free_fn)(void *ptr);
} cJSON_Hooks;//�ڴ����������newһ��cJSON�ڵ㣨��������������ָ��ýڵ�ĵ�ַ�� ע�ⷵ������Ϊ��cJSON *����
/* Internal constructor. */
static cJSON *cJSON_New_Item(void)
{
cJSON* node = (cJSON*)cJSON_malloc(sizeof(cJSON));//malloc��һ���ڵ�
if (node) memset(node,0,sizeof(cJSON));//���ڴ��ʼ��Ϊ0
return node;
}����˳��˵һ��cJSON�ṹ������ͣ�
/* The cJSON structure: */
typedef struct cJSON {
struct cJSON *next,*prev; //˫������ָ��
struct cJSON *child; //��һ�����ӵ�ָ�� �������õ������˵��
int type; /* The type of the item, as above. */
char *valuestring; /* The item's string, if type==cJSON_String */
int valueint; /* The item's number, if type==cJSON_Number */
double valuedouble; /* The item's number, if type==cJSON_Number */
char *string; //����Ƕ����key_valueԪ�صĻ��� keyֵ
} cJSON;
type:
/* cJSON Types: */ #define cJSON_False (1 << 0) #define cJSON_True (1 << 1) #define cJSON_NULL (1 << 2) #define cJSON_Number (1 << 3) #define cJSON_String (1 << 4) #define cJSON_Array (1 << 5) #define cJSON_Object (1 << 6)
//ɾ��һ��cJSON�ڵ㣬 ��ɾ�����ӽڵ㣬Ȼ��ɾ���Լ��������ַ�������Ҫ���ͷ��ַ������ڴ�Ȼ�����ͷ��Լ�������ڴ棬���������ڵ㣬ֱ���ͷ��Լ�����ڴ棨Ŀǰ������Ķ��ӽڵ㻹���е㲻���⣬���ӽڵ�(struct cJSON����)������ʲô�������õģ�ɾ����ʱ��ΪɶҪ�������������������
#define cJSON_IsReference 256
#define cJSON_StringIsConst 512
/* Delete a cJSON structure. */
void cJSON_Delete(cJSON *c)
{
cJSON *next;
while (c)
{
next=c->next;
if (!(c->type&cJSON_IsReference) && c->child)
cJSON_Delete(c->child); //�ȵݹ�ɾ���Լ��Ķ��ӽڵ�
if (!(c->type&cJSON_IsReference) && c->valuestring)
cJSON_free(c->valuestring);
if (!(c->type&cJSON_StringIsConst) && c->string)
cJSON_free(c->string);
cJSON_free(c);
c=next;
}
}//�������֣�Դ���格���������ģ��������Ķ������൱�����㣡�����Ķ�֮ǰ格ʽ�����Լ��ȵ���һ�£�
//���������ı�����һ������,���������
//����IJ�����������������ֻ��עnum�� ����值��һ���ַ���
<span style="font-size:18px;">/* Parse the input text to generate a number, and populate the result into item. */
static const char *parse_number(cJSON *item,const char *num)
{
double n=0,sign=1,scale=0;int subscale=0,signsubscale=1;
if (*num=='-') sign=-1,num++; /* �ж��Ƿ�Ϊ������ */
if (*num=='0') num++; /* is zero */
if (*num>='1' && *num<='9')
do n=(n*10.0)+(*num++ -'0'); while (*num>='0' && *num<='9'); //ע��һ���������������ֺ�
if (*num=='.' && num[1]>='0' && num[1]<='9') //��С�����ߵIJ��ֽ��д��� scale��¼С�����ߵ�λ��
{num++; do n=(n*10.0)+(*num++ -'0'),scale--; while (*num>='0' && *num<='9');}
if (*num=='e' || *num=='E') /* �Ƿ�Ϊָ������ѧ������ */
{ num++;if (*num=='+') num++; else if (*num=='-') signsubscale=-1,num++;//�ж�ָ������ݵ�������
while (*num>='0' && *num<='9') subscale=(subscale*10)+(*num++ - '0');//ָ�����10����
}
//���ַ���ת��Ϊ��Ӧ����ֵ
n=sign*n*pow(10.0,(scale+subscale*signsubscale));/* number = +/- number.fraction * 10^+/- exponent */
item->valuedouble=n;//���������ֵ���뻺��
item->valueint=(int)n;//ͬ��
item->type=cJSON_Number; //Ŀ������Ϊ����
return num;
}</span>
��ʵ����Ŀ������е㸴�ӣ�������ϸ������ʵ���Ǻܼģ���ľ������д����Ȼ����Լ��������һ��һ��ִ������Ĵ���Ȼ�����������Ҫ���ַ����Ŀ�ѧ������ת��Ϊ��ѧ�ϵĿ�ѧ��������
����next one!
static int pow2gt (int x)
{ --x; x|=x>>1; x|=x>>2; x|=x>>4; x|=x>>8; x|=x>>16; return x+1; }�²�һ�£�Դ�������ֱ����格��ĺܱ�Ť��__pow2gt(x) ��������, ���� һ����x �� n (����n��2����),��������С���ݣ�˵���˾��ǽ�һ����������е�λ����1Ȼ����+1���Լ���������������������֤һ�£����������int�ͣ�����Ǹ�����ô�죿�����û��֤�����������¿��ɣ�
typedef struct {char *buffer; int length; int offset; } printbuffer;
/* ensure ���� ��һ�� Э�� printbuffer �����ڴ��һ������
* len ��ʾ��ǰ�ַ������ַ�����ʼƫ���� �� newbuffer+p->offset ��ʼ��
*/
static char* ensure(printbuffer *p,int needed)
{
char *newbuffer;int newsize;
if (!p || !p->buffer) return 0;//��������Ϸ��Լ��
needed+=p->offset;//��Ҫ���������ڴ� Ҳ����ƫ����
if (needed<=p->length) return p->buffer+p->offset;//�ڴ湻��ֱ�ӷ���
newsize=pow2gt(needed);//���ò�˵����õĺ�����
newbuffer=(char*)cJSON_malloc(newsize);//malloc�����ڴ� ������ʲô����������Ƿ�buffer���������
if (!newbuffer) {cJSON_free(p->buffer);p->length=0,p->buffer=0;return 0;}
if (newbuffer) memcpy(newbuffer,p->buffer,p->length);//�������� ��һ���е㲻������ͼ��ΪɶҪ��������
cJSON_free(p->buffer);//�ͷŵ�֮ǰ��buffer
p->length=newsize;
p->buffer=newbuffer;
return newbuffer+p->offset;//ΪʲôҪ��������������������Ҫ����
}���������ŵĹ��ܾ���Э�������ڴ棬��û������ΪʲôҪ��ô������߱߿�������ɣ�static int update(printbuffer *p)
{
char *str;
if (!p || !p->buffer) return 0;
str=p->buffer+p->offset;
return p->offset+strlen(str);
}���ص���һ����ַ��ƫ���������ַ���str���ȵĵ�ַ��������char *strֻ�Ǹ��ֲ�ָ���������ָ��ָ��ԭ�е�buffer+offset��ַ��������ַ���������值��һ��int�ͣ�
//�ȿ���������������值������值Ϊһ���ַ�����ַ,�����sprintf�������÷���֪���ǽ�����ת��Ϊ�ַ������飡
//Ҳ���� 300ת��Ϊ��300��
static char *print_number(cJSON *item,printbuffer *p)
{
char *str=0;
double d=item->valuedouble;//ȡ��item�����valuedouble
if (d==0)
{
if (p) str=ensure(p,2);//���������ֽ��ڴ� ������pow2gt����
else str=(char*)cJSON_malloc(2); /* special case for 0. */
if (str) strcpy(str,"0");//��һ���ַ�0
}
else if (fabs(((double)item->valueint)-d)<=DBL_EPSILON && d<=INT_MAX && d>=INT_MIN)
{
if (p) str=ensure(p,21);
else str=(char*)cJSON_malloc(21); /* 2^64+1 can be represented in 21 chars. */
if (str) sprintf(str,"%d",item->valueint);
}
else
{
if (p) str=ensure(p,64);
else str=(char*)cJSON_malloc(64); /* This is a nice tradeoff. */
if (str)
{
if (fpclassify(d) != FP_ZERO && !isnormal(d))
sprintf(str,"null");
else if (fabs(floor(d)-d)<=DBL_EPSILON && fabs(d)<1.0e60)
sprintf(str,"%.0f",d);
else if (fabs(d)<1.0e-6 || fabs(d)>1.0e9)
sprintf(str,"%e",d);
else sprintf(str,"%f",d);
}
}
return str;
}����ĺ������и��ط����Թ�עһ��DBL_EPSILON ����next one!
//��ʮ�����Ƶ��ַ���ת��Ϊ���ֱ�ʾ����������Լ�Ҳ���Ե���д��С�������һ�£��Ƚϼ����ˣ�
static unsigned parse_hex4(const char *str)
{
unsigned h=0;
if (*str>='0' && *str<='9') h+=(*str)-'0';
else if (*str>='A' && *str<='F') h+=10+(*str)-'A';
else if (*str>='a' && *str<='f') h+=10+(*str)-'a';
else return 0;
h=h<<4;str++;
if (*str>='0' && *str<='9') h+=(*str)-'0';
else if (*str>='A' && *str<='F') h+=10+(*str)-'A';
else if (*str>='a' && *str<='f') h+=10+(*str)-'a';
else return 0;
h=h<<4;str++;
if (*str>='0' && *str<='9') h+=(*str)-'0';
else if (*str>='A' && *str<='F') h+=10+(*str)-'A';
else if (*str>='a' && *str<='f') h+=10+(*str)-'a';
else return 0;
h=h<<4;str++;
if (*str>='0' && *str<='9') h+=(*str)-'0';
else if (*str>='A' && *str<='F') h+=10+(*str)-'A';
else if (*str>='a' && *str<='f') h+=10+(*str)-'a';
else return 0;
return h;
}//�����ı�������һ����Ϊ���е��ַ���,�������
static const unsigned char firstByteMark[7] = { 0x00, 0x00, 0xC0, 0xE0, 0xF0, 0xF8, 0xFC };
static const char *parse_string(cJSON *item,const char *str,const char **ep)
{
const char *ptr=str+1,*end_ptr=str+1;char *ptr2;char *out;int len=0;unsigned uc,uc2;
if (*str!='\"') {*ep=str;return 0;} /* not a string! */
while (*end_ptr!='\"' && *end_ptr && ++len) if (*end_ptr++ == '\\') end_ptr++; /* Skip escaped quotes. */
out=(char*)cJSON_malloc(len+1); /* This is how long we need for the string, roughly. */
if (!out) return 0;
item->valuestring=out; /* assign here so out will be deleted during cJSON_Delete() later */
item->type=cJSON_String;
ptr=str+1;ptr2=out;
while (ptr < end_ptr)
{
if (*ptr!='\\') *ptr2++=*ptr++;
else
{
ptr++;
switch (*ptr)
{
case 'b': *ptr2++='\b'; break;
case 'f': *ptr2++='\f'; break;
case 'n': *ptr2++='\n'; break;
case 'r': *ptr2++='\r'; break;
case 't': *ptr2++='\t'; break;
case 'u': /* transcode utf16 to utf8. */
uc=parse_hex4(ptr+1);ptr+=4; /* get the unicode char. */
if (ptr >= end_ptr) {*ep=str;return 0;} /* invalid */
if ((uc>=0xDC00 && uc<=0xDFFF) || uc==0) {*ep=str;return 0;}
if (uc>=0xD800 && uc<=0xDBFF) /* UTF16 surrogate pairs. */
{
if (ptr+6 > end_ptr) {*ep=str;return 0;} /* invalid */
if (ptr[1]!='\\' || ptr[2]!='u') {*ep=str;return 0;}
uc2=parse_hex4(ptr+3);ptr+=6;
if (uc2<0xDC00 || uc2>0xDFFF) {*ep=str;return 0;}
uc=0x10000 + (((uc&0x3FF)<<10) | (uc2&0x3FF));
}
len=4;
if (uc<0x80) len=1;
else if (uc<0x800) len=2;
else if (uc<0x10000) len=3;
ptr2+=len;
switch (len) {
case 4: *--ptr2 =((uc | 0x80) & 0xBF); uc >>= 6;
case 3: *--ptr2 =((uc | 0x80) & 0xBF); uc >>= 6;
case 2: *--ptr2 =((uc | 0x80) & 0xBF); uc >>= 6;
case 1: *--ptr2 =(uc | firstByteMark[len]);
}
ptr2+=len;
break;
default: *ptr2++=*ptr; break;
}
ptr++;
}
}
*ptr2=0;
if (*ptr=='\"') ptr++;
return ptr;
}�����е㳤����������Ҳ���е�Ѿ������������Ĵ��幦�ܻ�������Ĵ������̻�ûŪ���ף��ȿ���ߣ����IJ���ٲ��Գ���ͨ������Ч���������ٿ���������ĺ�����������ֻ���ػ�ս���ˣ�//�����һ���������ܺ������࣬���ǽ��������ɿ��Դ�ӡ�������ַ���
static char *print_string_ptr(const char *str,printbuffer *p)
{
const char *ptr;char *ptr2,*out;int len=0,flag=0;unsigned char token;
if (!str)
{
if (p) out=ensure(p,3);
else out=(char*)cJSON_malloc(3);
if (!out) return 0;
strcpy(out,"\"\"");
return out;
}
for (ptr=str;*ptr;ptr++) flag|=((*ptr>0 && *ptr<32)||(*ptr=='\"')||(*ptr=='\\'))1:0;
if (!flag)
{
len=ptr-str;
if (p) out=ensure(p,len+3);
else out=(char*)cJSON_malloc(len+3);
if (!out) return 0;
ptr2=out;*ptr2++='\"';
strcpy(ptr2,str);
ptr2[len]='\"';
ptr2[len+1]=0;
return out;
}
ptr=str;
while ((token=*ptr) && ++len)
{if (strchr("\"\\\b\f\n\r\t",token)) len++; else if (token<32) len+=5;ptr++;}
if (p) out=ensure(p,len+3);
else out=(char*)cJSON_malloc(len+3);
if (!out) return 0;
ptr2=out;ptr=str;
*ptr2++='\"';
while (*ptr)
{
if ((unsigned char)*ptr>31 && *ptr!='\"' && *ptr!='\\') *ptr2++=*ptr++;
else
{
*ptr2++='\\';
switch (token=*ptr++)
{
case '\\': *ptr2++='\\'; break;
case '\"': *ptr2++='\"'; break;
case '\b': *ptr2++='b'; break;
case '\f': *ptr2++='f'; break;
case '\n': *ptr2++='n'; break;
case '\r': *ptr2++='r'; break;
case '\t': *ptr2++='t'; break;
default: sprintf(ptr2,"u%04x",token);ptr2+=5; break; /* escape and print */
}
}
}
*ptr2++='\"';*ptr2++=0;
return out;
}//����һ���װ ���ַ�����ʽ���
<span style="font-size:18px;">static char *print_string(cJSON *item,printbuffer *p) {return print_string_ptr(item->valuestring,p);}</span>//������格
<span style="font-size:18px;">static const char *skip(const char *in) {while (in && *in && (unsigned char)*in<=32) in++; return in;}</span>//����������һ���µĸ�����ʼ��������һ��cJSON����
cJSON *cJSON_ParseWithOpts(const char *value,const char **return_parse_end,int require_null_terminated)
{
const char *end=0,**ep=return_parse_endreturn_parse_end:&global_ep;
cJSON *c=cJSON_New_Item();
*ep=0;
if (!c) return 0; /* memory fail */
end=parse_value(c,skip(value),ep);
if (!end) {cJSON_Delete(c);return 0;} /* parse failure. ep is set. */
/* if we require null-terminated JSON without appended garbage, skip and then check for a null terminator */
if (require_null_terminated) {end=skip(end);if (*end) {cJSON_Delete(c);*ep=end;return 0;}}
if (return_parse_end) *return_parse_end=end;
return c;
}
/* Default options for cJSON_Parse */
cJSON *cJSON_Parse(const char *value) {return cJSON_ParseWithOpts(value,0,0);}
/* Render a cJSON item/entity/structure to text. */
char *cJSON_Print(cJSON *item) {return print_value(item,0,1,0);}
char *cJSON_PrintUnformatted(cJSON *item) {return print_value(item,0,0,0);}//�ȼ������¿�
char *cJSON_PrintBuffered(cJSON *item,int prebuffer,int fmt)
{
printbuffer p;
p.buffer=(char*)cJSON_malloc(prebuffer);
p.length=prebuffer;
p.offset=0;
return print_value(item,0,fmt,&p);
}
static const char *parse_value(cJSON *item,const char *value,const char **ep)
{
if (!value) return 0; /* Fail on null. */
if (!strncmp(value,"null",4)) { item->type=cJSON_NULL; return value+4; }
if (!strncmp(value,"false",5)) { item->type=cJSON_False; return value+5; }
if (!strncmp(value,"true",4)) { item->type=cJSON_True; item->valueint=1;return value+4; }
if (*value=='\"') { return parse_string(item,value,ep); }
if (*value=='-' || (*value>='0' && *value<='9')) { return parse_number(item,value); }
if (*value=='[') { return parse_array(item,value,ep); }
if (*value=='{') { return parse_object(item,value,ep); }
*ep=value;return 0; /* failure. */
}//�������� ���ڿ���������ĵĴ����� ����Ĵ������ǺϷ��Լ�⣬ʵ���ϴ���û����
static const char *parse_array(cJSON *item,const char *value,const char **ep)
{
cJSON *child;
if (*value!='[') {*ep=value;return 0;} /* not an array! */
item->type=cJSON_Array;
value=skip(value+1);
if (*value==']') return value+1; /* empty array. */
item->child=child=cJSON_New_Item();
if (!item->child) return 0; /* memory fail */
value=skip(parse_value(child,skip(value),ep)); /* skip any spacing, get the value. */
if (!value) return 0;
while (*value==',')
{
cJSON *new_item;
if (!(new_item=cJSON_New_Item())) return 0; /* memory fail */
child->next=new_item;new_item->prev=child;child=new_item;//ԭ��childָ����ָ��cJson�ڵ�ģ���������ָ����Ϊ˫������ָ��
value=skip(parse_value(child,skip(value+1),ep));
if (!value) return 0; /* memory fail */
}
if (*value==']') return value+1; /* end of array */
*ep=value;return 0; /* malformed. */
}//������������ͱȽϳ��ˣ�����值Ϊһ��Ҫout���ַ�������������Ľ������������Ƚϳ�һ�㣬���Զ����ź�ߵIJ��Գ���Ȼ����Խ��������������������������out���Ľ����Ȼ���ǰ��Լ�������������Ŵ���һ��һ��ִ�У��ȴ��������������̵ľ�����Ȼ��Ϳ��Իع�ͷ�����۴���ˣ�
static char *print_array(cJSON *item,int depth,int fmt,printbuffer *p)
{
char **entries;
char *out=0,*ptr,*ret;int len=5;
cJSON *child=item->child;
int numentries=0,i=0,fail=0;
size_t tmplen=0;
/* How many entries in the array */
while (child) numentries++,child=child->next;
/* Explicitly handle numentries==0 */
if (!numentries)
{
if (p) out=ensure(p,3);
else out=(char*)cJSON_malloc(3);
if (out) strcpy(out,"[]");
return out;
}
if (p)
{
/* Compose the output array. */
i=p->offset;
ptr=ensure(p,1);if (!ptr) return 0; *ptr='['; p->offset++;
child=item->child;
while (child && !fail)
{
print_value(child,depth+1,fmt,p);
p->offset=update(p);
if (child->next)
{
len=fmt2:1;ptr=ensure(p,len+1);
if (!ptr) return 0;*ptr++=',';
if(fmt)*ptr++=' ';*ptr=0;p->offset+=len;
}
child=child->next;
}
ptr=ensure(p,2);if (!ptr) return 0; *ptr++=']';*ptr=0;
out=(p->buffer)+i;
}
else
{
/* Allocate an array to hold the values for each */
entries=(char**)cJSON_malloc(numentries*sizeof(char*));
if (!entries) return 0;
memset(entries,0,numentries*sizeof(char*));
/* Retrieve all the results: */
child=item->child;
while (child && !fail)
{
ret=print_value(child,depth+1,fmt,0);
entries[i++]=ret;
if (ret) len+=strlen(ret)+2+(fmt1:0); else fail=1;
child=child->next;
}
/* If we didn't fail, try to malloc the output string */
if (!fail) out=(char*)cJSON_malloc(len);
/* If that fails, we fail. */
if (!out) fail=1;
/* Handle failure. */
if (fail)
{
for (i=0;i<numentries;i++) if (entries[i]) cJSON_free(entries[i]);
cJSON_free(entries);
return 0;
}
/* Compose the output array. */
*out='[';
ptr=out+1;*ptr=0;
for (i=0;i<numentries;i++)
{
tmplen=strlen(entries[i]);memcpy(ptr,entries[i],tmplen);ptr+=tmplen;
if (i!=numentries-1) {*ptr++=',';if(fmt)*ptr++=' ';*ptr=0;}
cJSON_free(entries[i]);
}
cJSON_free(entries);
*ptr++=']';*ptr++=0;
}
return out;
}�������������ǽ��������outһ���ַ�����ʽ�Ķ�����������APIһ��
/* Build an object from the text. */
static const char *parse_object(cJSON *item,const char *value,const char **ep)
{
cJSON *child;
if (*value!='{') {*ep=value;return 0;} /* not an object! */
item->type=cJSON_Object;
value=skip(value+1);
if (*value=='}') return value+1; /* empty array. */
item->child=child=cJSON_New_Item();
if (!item->child) return 0;
value=skip(parse_string(child,skip(value),ep));
if (!value) return 0;
child->string=child->valuestring;child->valuestring=0;
if (*value!=':') {*ep=value;return 0;} /* fail! */
value=skip(parse_value(child,skip(value+1),ep)); /* skip any spacing, get the value. */
if (!value) return 0;
while (*value==',')
{
cJSON *new_item;
if (!(new_item=cJSON_New_Item())) return 0; /* memory fail */
child->next=new_item;new_item->prev=child;child=new_item;
value=skip(parse_string(child,skip(value+1),ep));
if (!value) return 0;
child->string=child->valuestring;child->valuestring=0;
if (*value!=':') {*ep=value;return 0;} /* fail! */
value=skip(parse_value(child,skip(value+1),ep)); /* skip any spacing, get the value. */
if (!value) return 0;
}
if (*value=='}') return value+1; /* end of array */
*ep=value;return 0; /* malformed. */
}
/* Render an object to text. */
static char *print_object(cJSON *item,int depth,int fmt,printbuffer *p)
{
char **entries=0,**names=0;
char *out=0,*ptr,*ret,*str;int len=7,i=0,j;
cJSON *child=item->child;
int numentries=0,fail=0;
size_t tmplen=0;
/* Count the number of entries. */
while (child) numentries++,child=child->next;
/* Explicitly handle empty object case */
if (!numentries)
{
if (p) out=ensure(p,fmtdepth+4:3);
else out=(char*)cJSON_malloc(fmtdepth+4:3);
if (!out) return 0;
ptr=out;*ptr++='{';
if (fmt) {*ptr++='\n';for (i=0;i<depth;i++) *ptr++='\t';}
*ptr++='}';*ptr++=0;
return out;
}
if (p)
{
/* Compose the output: */
i=p->offset;
len=fmt2:1; ptr=ensure(p,len+1); if (!ptr) return 0;
*ptr++='{'; if (fmt) *ptr++='\n'; *ptr=0; p->offset+=len;
child=item->child;depth++;
while (child)
{
if (fmt)
{
ptr=ensure(p,depth); if (!ptr) return 0;
for (j=0;j<depth;j++) *ptr++='\t';
p->offset+=depth;
}
print_string_ptr(child->string,p);
p->offset=update(p);
len=fmt2:1;
ptr=ensure(p,len); if (!ptr) return 0;
*ptr++=':';if (fmt) *ptr++='\t';
p->offset+=len;
print_value(child,depth,fmt,p);
p->offset=update(p);
len=(fmt1:0)+(child->next1:0);
ptr=ensure(p,len+1); if (!ptr) return 0;
if (child->next) *ptr++=',';
if (fmt) *ptr++='\n';*ptr=0;
p->offset+=len;
child=child->next;
}
ptr=ensure(p,fmt(depth+1):2); if (!ptr) return 0;
if (fmt) for (i=0;i<depth-1;i++) *ptr++='\t';
*ptr++='}';*ptr=0;
out=(p->buffer)+i;
}
else
{
/* Allocate space for the names and the objects */
entries=(char**)cJSON_malloc(numentries*sizeof(char*));
if (!entries) return 0;
names=(char**)cJSON_malloc(numentries*sizeof(char*));
if (!names) {cJSON_free(entries);return 0;}
memset(entries,0,sizeof(char*)*numentries);
memset(names,0,sizeof(char*)*numentries);
/* Collect all the results into our arrays: */
child=item->child;depth++;if (fmt) len+=depth;
while (child && !fail)
{
names[i]=str=print_string_ptr(child->string,0);
entries[i++]=ret=print_value(child,depth,fmt,0);
if (str && ret) len+=strlen(ret)+strlen(str)+2+(fmt2+depth:0); else fail=1;
child=child->next;
}
/* Try to allocate the output string */
if (!fail) out=(char*)cJSON_malloc(len);
if (!out) fail=1;
/* Handle failure */
if (fail)
{
for (i=0;i<numentries;i++) {if (names[i]) cJSON_free(names[i]);if (entries[i]) cJSON_free(entries[i]);}
cJSON_free(names);cJSON_free(entries);
return 0;
}
/* Compose the output: */
*out='{';ptr=out+1;if (fmt)*ptr++='\n';*ptr=0;
for (i=0;i<numentries;i++)
{
if (fmt) for (j=0;j<depth;j++) *ptr++='\t';
tmplen=strlen(names[i]);memcpy(ptr,names[i],tmplen);ptr+=tmplen;
*ptr++=':';if (fmt) *ptr++='\t';
strcpy(ptr,entries[i]);ptr+=strlen(entries[i]);
if (i!=numentries-1) *ptr++=',';
if (fmt) *ptr++='\n';*ptr=0;
cJSON_free(names[i]);cJSON_free(entries[i]);
}
cJSON_free(names);cJSON_free(entries);
if (fmt) for (i=0;i<depth-1;i++) *ptr++='\t';
*ptr++='}';*ptr++=0;
}
return out;
}
/* Get Array size/item / object item. */
int cJSON_GetArraySize(cJSON *array)
{cJSON *c=array->child;int i=0;while(c)i++,c=c->next;return i;}//���ؽڵ�ĸ���
cJSON *cJSON_GetArrayItem(cJSON *array,int item)
{cJSON *c=arrayarray->child:0;while (c && item>0) item--,c=c->next; return c;}//���ص�item���ڵ��ַ
cJSON *cJSON_GetObjectItem(cJSON *object,const char *string)//ͬ�ϣ�ֻ�����Ͳ�һ��
{cJSON *c=objectobject->child:0;while (c && cJSON_strcasecmp(c->string,string)) c=c->next; return c;}
int cJSON_HasObjectItem(cJSON *object,const char *string)//���η�װ����ʱ��û����������������
{return cJSON_GetObjectItem(object,string)1:0;}
/* Utility for array list handling. */
static void suffix_object(cJSON *prev,cJSON *item)
{prev->next=item;item->prev=prev;}//��������������β����һ���ڵ�
/* Utility for handling references. */
static cJSON *create_reference(cJSON *item)
{
cJSON *ref=cJSON_New_Item();
if (!ref) return 0;
memcpy(ref,item,sizeof(cJSON));
ref->string=0;
ref->type|=cJSON_IsReference;// ��256���� 1 0000 0000��256�Ķ����Ʊ�ʾ��������ʱ�е㲻����
ref->next=ref->prev=0;//���ÿ�
return ref;
}
/* Add item to array/object. */
void cJSON_AddItemToArray(cJSON *array, cJSON *item)//��item�ڵ����array����
{
cJSON *c=array->child;
if (!item) return;
if (!c) {array->child=item;} //���Ϊ������ ֱ�Ӳ���
else
{while (c && c->next) c=c->next; suffix_object(c,item);}
}
//���ַ������ӽ�����
void cJSON_AddItemToObject(cJSON *object,const char *string,cJSON *item)
{
if (!item) return;
if (item->string) cJSON_free(item->string);
item->string=cJSON_strdup(string);
cJSON_AddItemToArray(object,item);
}
void cJSON_AddItemToObjectCS(cJSON *object,const char *string,cJSON *item)
{
if (!item) return;
if (!(item->type&cJSON_StringIsConst) && item->string)
cJSON_free(item->string);
item->string=(char*)string;
item->type|=cJSON_StringIsConst;//512 ��10 0000 0000b)
cJSON_AddItemToArray(object,item);
}
void cJSON_AddItemReferenceToArray(cJSON *array, cJSON *item)
{
cJSON_AddItemToArray(array,create_reference(item));
}
void cJSON_AddItemReferenceToObject(cJSON *object,const char *string,cJSON *item)
{
cJSON_AddItemToObject(object,string,create_reference(item));
}
cJSON *cJSON_DetachItemFromArray(cJSON *array,int which)//���������е�whichλ�õĽڵ㲢����
{
cJSON *c=array->child;
while (c && which>0) c=c->next,which--;//cָ���which���ڵ�
if (!c) return 0;
if (c->prev)
c->prev->next=c->next;
if (c->next)
c->next->prev=c->prev;
if (c==array->child)
array->child=c->next;
c->prev=c->next=0;
return c;
}
void cJSON_DeleteItemFromArray(cJSON *array,int which)
{
cJSON_Delete(cJSON_DetachItemFromArray(array,which));
}
//����ͬ�ϲ�� ֻ�����Ͳ�ͬ
cJSON *cJSON_DetachItemFromObject(cJSON *object,const char *string)
{
int i=0;
cJSON *c=object->child;
while (c && cJSON_strcasecmp(c->string,string)) i++,c=c->next;
if (c)
return cJSON_DetachItemFromArray(object,i);
return 0;
}
void cJSON_DeleteItemFromObject(cJSON *object,const char *string)
{
cJSON_Delete(cJSON_DetachItemFromObject(object,string));
}//�����APIҲ�Ǻ��IJ��֣�Ҫ�ú÷�������
/* Replace array/object items with new ones. */
void cJSON_InsertItemInArray(cJSON *array,int which,cJSON *newitem)//�������в���һ���µĽڵ�
{
cJSON *c=array->child;
while (c && which>0) c=c->next,which--;//�ȶ�λ���滻��λ��
if (!c) {cJSON_AddItemToArray(array,newitem);return;}
newitem->next=c;
newitem->prev=c->prev;
c->prev=newitem;
if (c==array->child)
array->child=newitem;
else
newitem->prev->next=newitem;
}
void cJSON_ReplaceItemInArray(cJSON *array,int which,cJSON *newitem)<span style="font-family: Tahoma, Arial, ����, 'Malgun Gothic'; widows: auto;">//���µĽڵ��滻ԭ�е�ijһ���ڵ�</span>
{
cJSON *c=array->child;
while (c && which>0) c=c->next,which--;
if (!c) return;
newitem->next=c->next;
newitem->prev=c->prev;
if (newitem->next)
newitem->next->prev=newitem;
if (c==array->child)
array->child=newitem;
else
newitem->prev->next=newitem;
c->next=c->prev=0;
cJSON_Delete(c);
}
void cJSON_ReplaceItemInObject(cJSON *object,const char *string,cJSON *newitem)//ͬ�ϣ�ֻ�ǻ�������
{
int i=0;
cJSON *c=object->child;
while(c && cJSON_strcasecmp(c->string,string))
i++,c=c->next;
if(c)
{
newitem->string=cJSON_strdup(string);
cJSON_ReplaceItemInArray(object,i,newitem);
}
}1.��Ҫ����˵����1����������
������JSON����cJSON *cJSON_CreateObject(void);
������JSON���顿cJSON *cJSON_CreateArray(void);
��2����������
������������ӡ�voidcJSON_AddItemToObject(cJSON *object,const char *string,cJSON *item);
�������������ӡ�void cJSON_AddItemToArray(cJSON *array, cJSON *item);
��3�����ü���
����������������֡�cJSON_AddItemToObject(root, "value", cJSON_CreateNumber(value));
��������������ļ���cJSON_AddItemToObject(root, "string", cJSON_CreateString(string));
��4��JSONǶ��
����������������顿cJSON_AddItemToObject(root, "rows", rows = cJSON_CreateArray());
�������������Ӷ���cJSON_AddItemToArray(rows, row = cJSON_CreateObject());
����˵����
��1��cJSON_AddItemToObject(root, "value", cJSON_CreateNumber(value));
��2��cJSON_AddNumberToObject(root, "value", value);
��1���͡�2��Ч����ȫ��ͬ��
����˵����
��1�� cJSON_AddItemToObject(root, "name", cJSON_CreateString(name));
��2�� cJSON_AddStringToObject(root, "name",name);
��1���͡�2��Ч����ȫ��ͬ��
//Դ���格ʽ����������һ��
/* Create basic types: */
cJSON *cJSON_CreateNull(void)
{
cJSON *item=cJSON_New_Item();
if(item)
item->type=cJSON_NULL;
return item;
}
cJSON *cJSON_CreateTrue(void)
{
cJSON *item=cJSON_New_Item();
if(item)
item->type=cJSON_True;
return item;
}
cJSON *cJSON_CreateFalse(void)
{
cJSON *item=cJSON_New_Item();
if(item)
item->type=cJSON_False;
return item;
}
cJSON *cJSON_CreateBool(int b)
{
cJSON *item=cJSON_New_Item();
if(item)
item->type=bcJSON_True:cJSON_False;
return item;
}
cJSON *cJSON_CreateNumber(double num)
{
cJSON *item=cJSON_New_Item();
if(item)
{
item->type=cJSON_Number;
item->valuedouble=num;
item->valueint=(int)num;
}
return item;
}
cJSON *cJSON_CreateString(const char *string)
{
cJSON *item=cJSON_New_Item();
if(item)
{
item->type=cJSON_String;
item->valuestring=cJSON_strdup(string);
if(!item->valuestring)
{
cJSON_Delete(item);
return 0;
}
}
return item;
}
cJSON *cJSON_CreateArray(void)
{
cJSON *item=cJSON_New_Item();
if(item)
item->type=cJSON_Array;
return item;
}
cJSON *cJSON_CreateObject(void)
{
cJSON *item=cJSON_New_Item();
if(item)
item->type=cJSON_Object;
return item;
}�ϵ�API�����ʼǼ�����Ͳ������ˣ�//������ĸ�API����ֻ࣬�Ǵ�����ͬ���͵�����
/* Create Arrays: */
cJSON *cJSON_CreateIntArray(const int *numbers,int count)
{
int i;cJSON *n=0,*p=0,*a=cJSON_CreateArray();
for(i=0;a && i<count;i++)
{
n=cJSON_CreateNumber(numbers[i]);//���cJSON *n �IJ��ֽṹ�����忴���溯��ʵ��
if(!n){cJSON_Delete(a);return 0;}
if(!i)
a->child=n;
else
suffix_object(p,n);//����ڵ�
p=n;
}
return a;
}
cJSON *cJSON_CreateFloatArray(const float *numbers,int count)
{
int i;cJSON *n=0,*p=0,*a=cJSON_CreateArray();
for(i=0;a && i<count;i++)
{
n=cJSON_CreateNumber(numbers[i]);
if(!n){cJSON_Delete(a);return 0;}
if(!i)
a->child=n;
else
suffix_object(p,n);
p=n;
}
return a;
}
cJSON *cJSON_CreateDoubleArray(const double *numbers,int count)
{
int i;cJSON *n=0,*p=0,*a=cJSON_CreateArray();
for(i=0;a && i<count;i++)
{
n=cJSON_CreateNumber(numbers[i]);
if(!n){cJSON_Delete(a);return 0;}
if(!i)
a->child=n;
else
suffix_object(p,n);
p=n;
}
return a;
}
cJSON *cJSON_CreateStringArray(const char **strings,int count)
{
int i;cJSON *n=0,*p=0,*a=cJSON_CreateArray();
for(i=0;a && i<count;i++)
{
n=cJSON_CreateString(strings[i]);
if(!n){cJSON_Delete(a);return 0;}
if(!i)
a->child=n;
else
suffix_object(p,n);
p=n;
}
return a;
}//�������API
/* Duplication */
cJSON *cJSON_Duplicate(cJSON *item,int recurse)//�������� �Ƿ�ݹ鿽��
{
cJSON *newitem,*cptr,*nptr=0,*newchild;
if (!item) return 0;
/* Create new item */
newitem=cJSON_New_Item();
if (!newitem) return 0;
/* Copy over all vars */
newitem->type=item->type&(~cJSON_IsReference),newitem->valueint=item->valueint,newitem->valuedouble=item->valuedouble;
if (item->valuestring)
{
newitem->valuestring=cJSON_strdup(item->valuestring);
if (!newitem->valuestring) {cJSON_Delete(newitem);return 0;}
}
if (item->string)
{
newitem->string=cJSON_strdup(item->string);
if (!newitem->string) {cJSON_Delete(newitem);return 0;}
}
/* If non-recursive, then we're done! */
if (!recurse) return newitem;
/* Walk the ->next chain for the child. */
cptr=item->child;
while (cptr)
{
newchild=cJSON_Duplicate(cptr,1);
if (!newchild) {cJSON_Delete(newitem);return 0;}
if (nptr)
{
nptr->next=newchild,newchild->prev=nptr;
nptr=newchild;
}
else {newitem->child=newchild;nptr=newchild;}
cptr=cptr->next;
}
return newitem;
}
void cJSON_Minify(char *json)
{
char *into=json;
while (*json)
{
if (*json==' ') json++;
else if (*json=='\t') json++; /* Whitespace characters. */
else if (*json=='\r') json++;
else if (*json=='\n') json++;
else if (*json=='/' && json[1]=='/') while (*json && *json!='\n') json++;
else if (*json=='/' && json[1]=='*') {while (*json && !(*json=='*' && json[1]=='/')) json++;json+=2;} /* multiline comments. */
else if (*json=='\"'){*into++=*json++;while (*json && *json!='\"'){if (*json=='\\') *into++=*json++;*into++=*json++;}*into++=*json++;}
else *into++=*json++; /* All other characters. */
}
*into=0; /* and null-terminate. */
}cJSON.h
#ifndef cJSON__h
#define cJSON__h
#ifdef __cplusplus
extern "C"
{
#endif
/* cJSON Types: */
#define cJSON_False (1 << 0)
#define cJSON_True (1 << 1)
#define cJSON_NULL (1 << 2)
#define cJSON_Number (1 << 3)
#define cJSON_String (1 << 4)
#define cJSON_Array (1 << 5)
#define cJSON_Object (1 << 6)
#define cJSON_IsReference 256
#define cJSON_StringIsConst 512
/* The cJSON structure: */
typedef struct cJSON {
/* next/prev allow you to walk array/object chains. Alternatively, use GetArraySize/GetArrayItem/GetObjectItem */
struct cJSON *next,*prev;
/* An array or object item will have a child pointer pointing to a chain of the items in the array/object. */
struct cJSON *child;
int type; /* The type of the item, as above. */
char *valuestring; /* The item's string, if type==cJSON_String */
int valueint; /* The item's number, if type==cJSON_Number */
double valuedouble; /* The item's number, if type==cJSON_Number */
/* The item's name string, if this item is the child of, or is in the list of subitems of an object. */
char *string;
} cJSON;
typedef struct cJSON_Hooks {
void *(*malloc_fn)(size_t sz);
void (*free_fn)(void *ptr);
} cJSON_Hooks;
/* Supply malloc, realloc and free functions to cJSON */
extern void cJSON_InitHooks(cJSON_Hooks* hooks);
extern cJSON *cJSON_Parse(const char *value);
/* Render a cJSON entity to text for transfer/storage. Free the char* when finished. */
extern char *cJSON_Print(cJSON *item);
extern char *cJSON_PrintUnformatted(cJSON *item);
/* Render a cJSON entity to text using a buffered strategy. prebuffer is a guess at the final size.
*guessing well reduces reallocation. fmt=0 gives unformatted, =1 gives formatted
*/
extern char *cJSON_PrintBuffered(cJSON *item,int prebuffer,int fmt);
/* Delete a cJSON entity and all subentities. */
extern void cJSON_Delete(cJSON *c);
/* Returns the number of items in an array (or object). */
extern int cJSON_GetArraySize(cJSON *array);
/* Retrieve item number "item" from array "array". Returns NULL if unsuccessful. */
extern cJSON *cJSON_GetArrayItem(cJSON *array,int item);
/* Get item "string" from object. Case insensitive. */
extern cJSON *cJSON_GetObjectItem(cJSON *object,const char *string);
extern int cJSON_HasObjectItem(cJSON *object,const char *string);
/* For analysing failed parses. This returns a pointer to the parse error.
* You'll probably need to look a few chars back to make sense of it.
Defined when cJSON_Parse() returns 0. 0 when cJSON_Parse() succeeds.
*/
extern const char *cJSON_GetErrorPtr(void);
/* These calls create a cJSON item of the appropriate type. */
extern cJSON *cJSON_CreateNull(void);
extern cJSON *cJSON_CreateTrue(void);
extern cJSON *cJSON_CreateFalse(void);
extern cJSON *cJSON_CreateBool(int b);
extern cJSON *cJSON_CreateNumber(double num);
extern cJSON *cJSON_CreateString(const char *string);
extern cJSON *cJSON_CreateArray(void);
extern cJSON *cJSON_CreateObject(void);
/* These utilities create an Array of count items. */
extern cJSON *cJSON_CreateIntArray(const int *numbers,int count);
extern cJSON *cJSON_CreateFloatArray(const float *numbers,int count);
extern cJSON *cJSON_CreateDoubleArray(const double *numbers,int count);
extern cJSON *cJSON_CreateStringArray(const char **strings,int count);
/* Append item to the specified array/object. */
extern void cJSON_AddItemToArray(cJSON *array, cJSON *item);
extern void cJSON_AddItemToObject(cJSON *object,const char *string,cJSON *item);
extern void cJSON_AddItemToObjectCS(cJSON *object,const char *string,cJSON *item);
/* Append reference to item to the specified array/object. Use this when you want to
* add an existing cJSON to a new cJSON, but don't want to corrupt your existing cJSON.
*/
extern void cJSON_AddItemReferenceToArray(cJSON *array, cJSON *item);
extern void cJSON_AddItemReferenceToObject(cJSON *object,const char *string,cJSON *item);
/* Remove/Detatch items from Arrays/Objects. */
extern cJSON *cJSON_DetachItemFromArray(cJSON *array,int which);
extern void cJSON_DeleteItemFromArray(cJSON *array,int which);
extern cJSON *cJSON_DetachItemFromObject(cJSON *object,const char *string);
extern void cJSON_DeleteItemFromObject(cJSON *object,const char *string);
/* Update array items. */
extern void cJSON_InsertItemInArray(cJSON *array,int which,cJSON *newitem);
extern void cJSON_ReplaceItemInArray(cJSON *array,int which,cJSON *newitem);
extern void cJSON_ReplaceItemInObject(cJSON *object,const char *string,cJSON *newitem);
/* Duplicate a cJSON item */
extern cJSON *cJSON_Duplicate(cJSON *item,int recurse);
/* Duplicate will create a new, identical cJSON item to the one you pass, in new memory that will
*need to be released. With recurse!=0, it will duplicate any children connected to the item.
*The item->next and ->prev pointers are always zero on return from Duplicate.
*/
/* ParseWithOpts allows you to require (and check) that the JSON is null terminated,
*and to retrieve the pointer to the final byte parsed.
*/
extern cJSON *cJSON_ParseWithOpts(const char *value,const char **return_parse_end,int require_null_terminated);
extern void cJSON_Minify(char *json);
Makefile (���Makefile ���Խ�Ŀ���ļ��������̬�⣬��̬�⣬�Դ��IJ��Գ�������Ŀ���ļ���������������С����˵���Ǻ�值��ѧϰ�о���)
OBJ = cJSON.o LIBNAME = libcjson TESTS = test PREFIX = /usr/local INCLUDE_PATH = include/cjson LIBRARY_PATH = lib INSTALL_INCLUDE_PATH = $(DESTDIR)$(PREFIX)/$(INCLUDE_PATH) INSTALL_LIBRARY_PATH = $(DESTDIR)$(PREFIX)/$(LIBRARY_PATH) INSTALL = cp -a R_CFLAGS = -fpic $(CFLAGS) -Wall -Werror -Wstrict-prototypes -Wwrite-strings -D_POSIX_C_SOURCE=200112L uname_S := $(shell sh -c 'uname -s 2>/dev/null || echo false') ## shared lib DYLIBNAME = $(LIBNAME).so DYLIBCMD = $(CC) -shared -o $(DYLIBNAME) ## create dynamic (shared) library on Darwin (base OS for MacOSX and IOS) ifeq (Darwin, $(uname_S)) DYLIBNAME = $(LIBNAME).dylib ## create dyanmic (shared) library on SunOS else ifeq (SunOS, $(uname_S)) DYLIBCMD = $(CC) -G -o $(DYLIBNAME) INSTALL = cp -r endif ## static lib STLIBNAME = $(LIBNAME).a .PHONY: all clean install all: $(DYLIBNAME) $(STLIBNAME) $(TESTS) $(DYLIBNAME): $(OBJ) $(DYLIBCMD) $< $(LDFLAGS) $(STLIBNAME): $(OBJ) ar rcs $@ $< $(OBJ): cJSON.c cJSON.h .c.o: $(CC) -ansi -pedantic -c $(R_CFLAGS) $< $(TESTS): cJSON.c cJSON.h test.c $(CC) cJSON.c test.c -o test -lm -I. install: $(DYLIBNAME) $(STLIBNAME) mkdir -p $(INSTALL_LIBRARY_PATH) $(INSTALL_INCLUDE_PATH) $(INSTALL) cJSON.h $(INSTALL_INCLUDE_PATH) $(INSTALL) $(DYLIBNAME) $(INSTALL_LIBRARY_PATH) $(INSTALL) $(STLIBNAME) $(INSTALL_LIBRARY_PATH) uninstall: rm -rf $(INSTALL_LIBRARY_PATH)/$(DYLIBNAME) rm -rf $(INSTALL_LIBRARY_PATH)/$(STLIBNAME) rm -rf $(INSTALL_INCLUDE_PATH)/cJSON.h clean: rm -rf $(DYLIBNAME) $(STLIBNAME) $(TESTS) *.o
test.c
#include <stdio.h>
#include <stdlib.h>
#include "cJSON.h"
/* Parse text to JSON, then render back to text, and print! */
void doit(char *text)
{
char *out;cJSON *json;
json=cJSON_Parse(text);
if (!json) {printf("Error before: [%s]\n",cJSON_GetErrorPtr());}
else
{
out=cJSON_Print(json);
cJSON_Delete(json);
printf("%s\n",out);
free(out);
}
}
/* Read a file, parse, render back, etc. */
void dofile(char *filename)
{
FILE *f;long len;char *data;
f=fopen(filename,"rb");fseek(f,0,SEEK_END);len=ftell(f);fseek(f,0,SEEK_SET);
data=(char*)malloc(len+1);fread(data,1,len,f);data[len]='\0';fclose(f);
doit(data);
free(data);
}
/* Used by some code below as an example datatype. */
struct record {const char *precision;double lat,lon;const char *address,*city,*state,*zip,*country; };
/* Create a bunch of objects as demonstration. */
void create_objects()
{
cJSON *root,*fmt,*img,*thm,*fld;char *out;int i; /* declare a few. */
/* Our "days of the week" array: */
const char *strings[7]={"Sunday","Monday","Tuesday","Wednesday","Thursday","Friday","Saturday"};
/* Our matrix: */
int numbers[3][3]={{0,-1,0},{1,0,0},{0,0,1}};
/* Our "gallery" item: */
int ids[4]={116,943,234,38793};
/* Our array of "records": */
struct record fields[2]={
{"zip",37.7668,-1.223959e+2,"","SAN FRANCISCO","CA","94107","US"},
{"zip",37.371991,-1.22026e+2,"","SUNNYVALE","CA","94085","US"}};
/* Here we construct some JSON standards, from the JSON site. */
/* Our "Video" datatype: */
root=cJSON_CreateObject();
cJSON_AddItemToObject(root, "name", cJSON_CreateString("Jack (\"Bee\") Nimble"));
cJSON_AddItemToObject(root, "format", fmt=cJSON_CreateObject());
cJSON_AddStringToObject(fmt,"type", "rect");
cJSON_AddNumberToObject(fmt,"width", 1920);
cJSON_AddNumberToObject(fmt,"height", 1080);
cJSON_AddFalseToObject (fmt,"interlace");
cJSON_AddNumberToObject(fmt,"frame rate", 24);
out=cJSON_Print(root); cJSON_Delete(root); printf("%s\n",out); free(out); /* Print to text, Delete the cJSON, print it, release the string. */
/* Our "days of the week" array: */
root=cJSON_CreateStringArray(strings,7);
out=cJSON_Print(root); cJSON_Delete(root); printf("%s\n",out); free(out);
/* Our matrix: */
root=cJSON_CreateArray();
for (i=0;i<3;i++) cJSON_AddItemToArray(root,cJSON_CreateIntArray(numbers[i],3));
/* cJSON_ReplaceItemInArray(root,1,cJSON_CreateString("Replacement")); */
out=cJSON_Print(root); cJSON_Delete(root); printf("%s\n",out); free(out);
/* Our "gallery" item: */
root=cJSON_CreateObject();
cJSON_AddItemToObject(root, "Image", img=cJSON_CreateObject());
cJSON_AddNumberToObject(img,"Width",800);
cJSON_AddNumberToObject(img,"Height",600);
cJSON_AddStringToObject(img,"Title","View from 15th Floor");
cJSON_AddItemToObject(img, "Thumbnail", thm=cJSON_CreateObject());
cJSON_AddStringToObject(thm, "Url", "http:/*www.example.com/image/481989943");
cJSON_AddNumberToObject(thm,"Height",125);
cJSON_AddStringToObject(thm,"Width","100");
cJSON_AddItemToObject(img,"IDs", cJSON_CreateIntArray(ids,4));
out=cJSON_Print(root); cJSON_Delete(root); printf("%s\n",out); free(out);
/* Our array of "records": */
root=cJSON_CreateArray();
for (i=0;i<2;i++)
{
cJSON_AddItemToArray(root,fld=cJSON_CreateObject());
cJSON_AddStringToObject(fld, "precision", fields[i].precision);
cJSON_AddNumberToObject(fld, "Latitude", fields[i].lat);
cJSON_AddNumberToObject(fld, "Longitude", fields[i].lon);
cJSON_AddStringToObject(fld, "Address", fields[i].address);
cJSON_AddStringToObject(fld, "City", fields[i].city);
cJSON_AddStringToObject(fld, "State", fields[i].state);
cJSON_AddStringToObject(fld, "Zip", fields[i].zip);
cJSON_AddStringToObject(fld, "Country", fields[i].country);
}
/* cJSON_ReplaceItemInObject(cJSON_GetArrayItem(root,1),"City",cJSON_CreateIntArray(ids,4)); */
out=cJSON_Print(root); cJSON_Delete(root); printf("%s\n",out); free(out);
root=cJSON_CreateObject();
cJSON_AddNumberToObject(root,"number", 1.0/0.0);
out=cJSON_Print(root); cJSON_Delete(root); printf("%s\n",out); free(out);
}
int main (int argc, const char * argv[]) {
/* a bunch of json: */
char text1[]="{\n\"name\": \"Jack (\\\"Bee\\\") Nimble\", \n\"format\": {\"type\": \"rect\", \n\"width\": 1920, \n\"height\": 1080, \n\"interlace\": false,\"frame rate\": 24\n}\n}";
char text2[]="[\"Sunday\", \"Monday\", \"Tuesday\", \"Wednesday\", \"Thursday\", \"Friday\", \"Saturday\"]";
char text3[]="[\n [0, -1, 0],\n [1, 0, 0],\n [0, 0, 1]\n ]\n";
char text4[]="{\n \"Image\": {\n \"Width\": 800,\n \"Height\": 600,\n \"Title\": \"View from 15th Floor\",\n \"Thumbnail\": {\n \"Url\": \"http:/*www.example.com/image/481989943\",\n \"Height\": 125,\n \"Width\": \"100\"\n },\n \"IDs\": [116, 943, 234, 38793]\n }\n }";
char text5[]="[\n {\n \"precision\": \"zip\",\n \"Latitude\": 37.7668,\n \"Longitude\": -122.3959,\n \"Address\": \"\",\n \"City\": \"SAN FRANCISCO\",\n \"State\": \"CA\",\n \"Zip\": \"94107\",\n \"Country\": \"US\"\n },\n {\n \"precision\": \"zip\",\n \"Latitude\": 37.371991,\n \"Longitude\": -122.026020,\n \"Address\": \"\",\n \"City\": \"SUNNYVALE\",\n \"State\": \"CA\",\n \"Zip\": \"94085\",\n \"Country\": \"US\"\n }\n ]";
char text6[] = "<!DOCTYPE html>"
"<html>\n"
"<head>\n"
" <meta name=\"viewport\" content=\"width=device-width, initial-scale=1\">\n"
" <style type=\"text/css\">\n"
" html, body, iframe { margin: 0; padding: 0; height: 100%; }\n"
" iframe { display: block; width: 100%; border: none; }\n"
" </style>\n"
"<title>Application Error</title>\n"
"</head>\n"
"<body>\n"
" <iframe src="//s3.amazonaws.com/heroku_pages/error.html">\n"
" <p>Application Error</p>\n"
" </iframe>\n"
"</body>\n"
"</html>\n";
/* Process each json textblock by parsing, then rebuilding: */
doit(text1);
doit(text2);
doit(text3);
doit(text4);
doit(text5);
doit(text6);
/* Parse standard testfiles: */
/* dofile("../../tests/test1"); */
/* dofile("../../tests/test2"); */
/* dofile("../../tests/test3"); */
/* dofile("../../tests/test4"); */
/* dofile("../../tests/test5"); */
/* dofile("../../tests/test6"); */
/* Now some samplecode for building objects concisely: */
create_objects();
return 0;
}
��������Ч�����ֽ�ͼ��
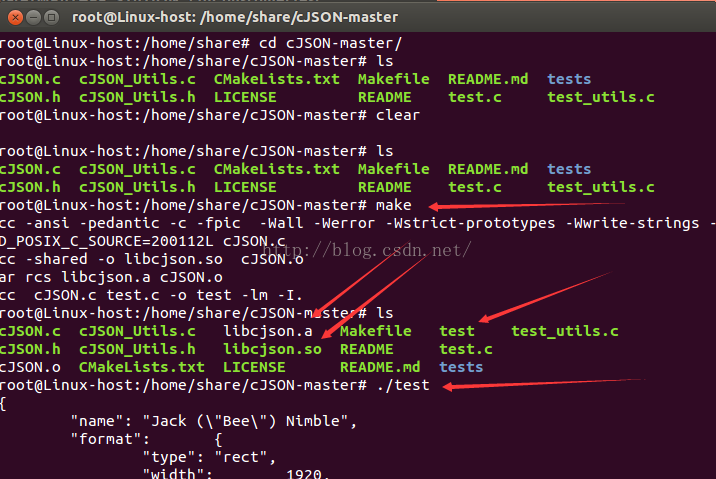
�����test.c��Ҳ����һ��һ���IJ��ԣ���Բ��������������еĽ���ٷ���������Դ�룡������������Ҳ�������һ�㣡����������doit�������õļ���������ϵ��

�������������ѹ���cjson�IJ������£����Խ�ϲο���������
http://blog.csdn.net/xukai871105/article/details/33013455
http://blog.sina.com.cn/s/blog_a6fb6cc90101ffme.html
http://blog.sina.com.cn/s/blog_5f28333901017kql.html
http://www.0xffffff.org/2014/02/10/29-cjson-analyse/
Դ���߽��ŷ�����δ�꣡
- ��
- 1
- ��
- 0
excel�����������������������������
yershop�̳�ϵͳ����һ����thinkphp��oneth
013--Floyd�㷨-��̬�滮-���㷨��Ƽ�����
���Visual Studio 2010��TFS����������
���������Ķ�����
-
excel��ô������������������������������ݺϲ�
2014-10-15
-
2016-06-06
-

2013-05-06
-
yershop�̳�ϵͳ����һ����thinkphp��onethink����
2016-06-08
-

-

���Visual Studio 2010��TFS��������������
2014-05-30
-
2016-06-06
-
2013-05-06
��������
-

2022-03-16
-
shell�ű���ζ�ȡproperties�ļ��е�ֵ
2022-03-16
-

2022-03-16
-
Redis֮RedisTemplate���÷�ʽ(���кͷ����л�)
2022-03-16
-
2022-03-16
-
2022-03-16
-
redis��������������ʹ���������
2022-03-16
-

��ڹ���һ��һֱ������ƵԴ��APP���Ѱ���µ�ͻ�ƿڣ�
2019-07-10
����Դ��
